Using Spira with Jira Cloud¶
Compatible with SpiraTest, SpiraTeam, SpiraPlan
Overview¶
Teams can work seamlessly using both Spira and Jira Cloud, using Inflectra's Jira Cloud data sync engine to keep key information in sync between both applications.
Real world example
- The QA team uses Spira for requirements and test management.
- When the QA team finds bugs during testing incidents are created in Spira, and then sync to Jira
- The Dev team manages the bug in Jira, with changes reflected back in Spira
This data sync plugin can sync the following information (what exactly syncs and is user configurable are discussed more below).
| Jira artifact | Spira artifact |
|---|---|
| Project | Product |
| Users | Users |
| Versions | Releases |
| Issues | Incidents and Requirements |
| Sub-tasks | Tasks |
| Comments | Comments |
| Attachments | Documents |
The table below shows a summary of how data is synced from/to Spira and Jira Cloud. The Jira datasync gives you a range of different syncing modes, depending on your workflows and needs.
| Sync Mode | Releases | Requirements | Incidents | Tasks |
|---|---|---|---|---|
| Default | Jira <-> Spira | Jira -> Spira | New: Jira <-> Spira Updates: Jira -> Spira |
New: Jira <- Spira Updates: Jira -> Spira |
| Bidirectional | Jira <-> Spira | Jira -> Spira | Jira <-> Spira | New: Jira <- Spira Updates: Jira -> Spira |
| Complete | Jira <-> Spira | Jira <-> Spira | Jira <-> Spira | Jira <-> Spira |
| NoRequirements | Jira <-> Spira | (not synced) | New: Jira <- Spira Updates: Jira -> Spira |
New: Jira <- Spira Updates: Jira -> Spira |
| NoIncidents | Jira <-> Spira | Jira -> Spira | (not synced) | New: Jira <- Spira Updates: Jira -> Spira |
Notes about syncing:
- The Default sync mode is the best for when the dev team uses Jira, and the QA team uses Spira. Devs in Jira create and manage requirements/user stories, so these sync one-way to Spira. Spira users can see incidents created in Jira, but bugs reported by QA can be seen in Jira. After bug creation, Jira users are in charge of updates, which sync back to Spira.
- The Bidirectional sync mode is similar to default, except that incidents fully sync both ways - for new incidents/issues, and their updates.
- The Complete sync mode allows fully bidirectional sync upon creation and update of all the supported artifacts (Releases, Requirements, Incidents, and Tasks).
- The NoRequirements sync mode is for when Spira is used to create new incidents and tasks, but Jira is used as the system where incidents and tasks are updated.
- The NoIncidents sync mode is for when you want to mainly sync requirements (or tasks) between Spira and Jira, but not incidents. In the other modes, incidents are the default artifact that syncs, but this mode sets requirements to be the default artifact. This means all the Jira Issue types will sync against Requirements or Tasks (if Task Types are configured).
- Users are not synced - instead Jira users are mapped to existing Spira users, wherever possible.
- Comments are synced bidirectionally by default between Spira and Jira Cloud. You can disable comments syncing using the option on the configuration page.
- Spira artifact tags sync as Jira labels and vice-versa, in the way supported by the sync mode
- Attachments are created in the other system when new artifacts/issues are created or existing ones are updated. Optionally, you can turn off the sync of attachments between the systems by adding an extra parameter to the field Sync Mode.
- If you are syncing Requirements, you can optionally sync the Epic/Story hierarchy from Jira to Spira Requirements and vice-versa.
- If you have two separated Jira instances to sync from/to, please follow these instructions to set up a second DataSync plugin without data duplication
Checklist¶
For the data sync to work correctly make sure you meet all of the steps below:
- Use Spira v8.10+
- Use Jira Cloud (we have a separate data sync for Jira Server / DataCenter)
- Setup a datasync service - either in Inflectra's cloud or on your own servers
- Download the Jira configuration helper application
- Configure the plugin in Spira
- Configure system wide user mapping
Then, for each product you want to sync:
- Activate the datasync
- Configure release mappings
- Configure standard field data mappings
- Configure custom field data mappings
Configure the Plugin¶
Make sure you have setup a datasync service before going further
- Login to Spira as a system administrator
- Go to System Administration > Integrations > Data Synchronization
- Find the plugin called JiraDataSync and click the "Edit" button to open the settings page
What to do if the plugin is not there
If you don't see the plug-in in the list, click the "Add" button at the top of the page. This opens the generic Data Sync plug-in details page. This is not yet customized to help you more easily set up the data sync. We recommend adding just enough information now to create the plug-in. Then edit the plug-in after it's made to complete the process.
To start, fill in the following fields:
- Name: enter "JiraDataSync" exactly
- Connection Info: enter the full URL to the Jira instance (see "Jira URL" below)
- Login: enter your Atlassian cloud login
Now click "Add" to save the plug-in and return you to the list of plug-ins. Now follow the instructions below.
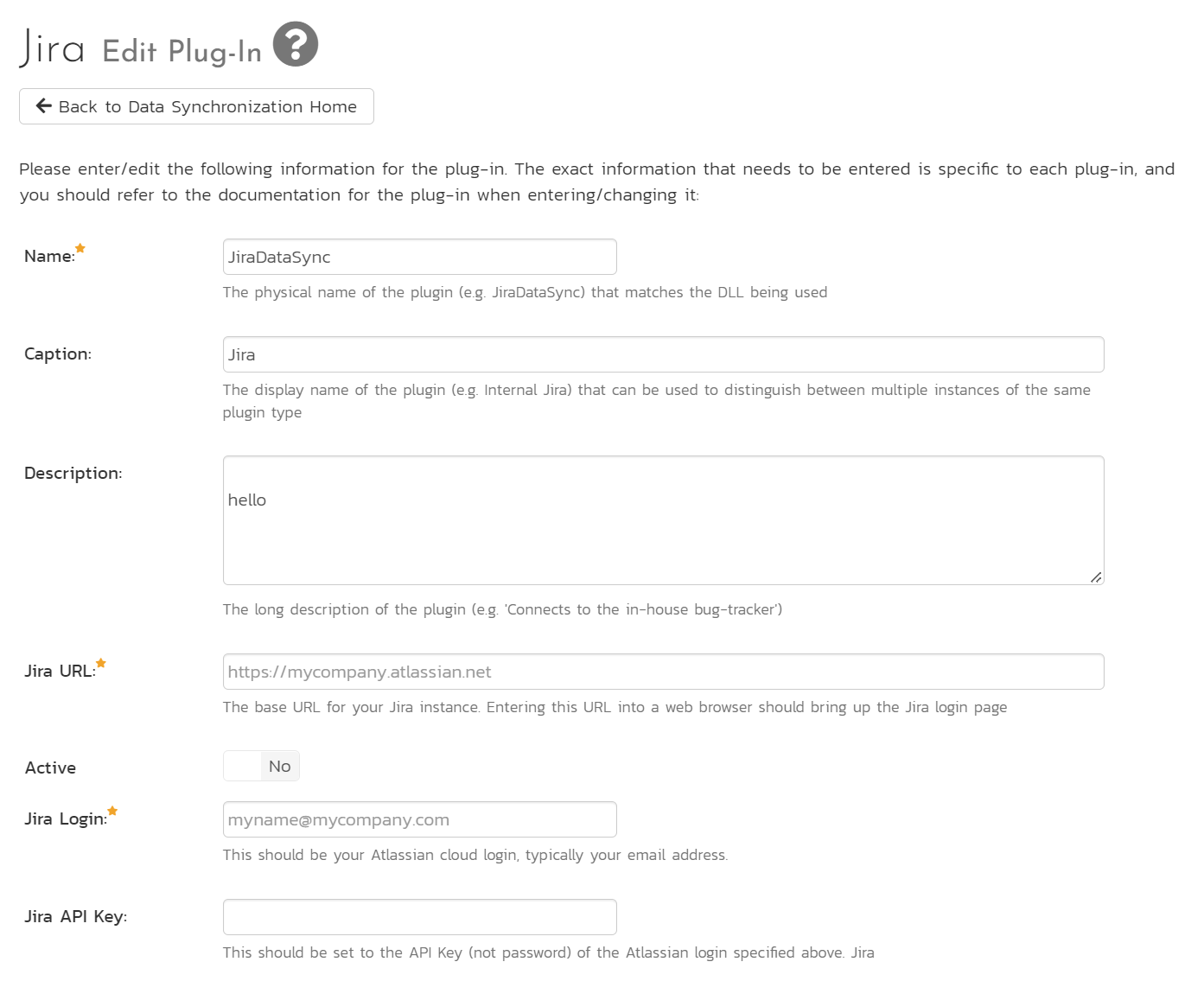
You need to fill in the following fields for the plugin to operate correctly:
- Name: (leave this as JiraDataSync)
- Caption: this is the plugin's display name. Put something like "Jira" or leave it blank. If you have multiple Jira instances, you will need a separate plugin for each one. Each plugin needs the same name so use the caption field to make it clear each one is different
- Description: this is an optional field you can use to help describe to your future self the setup and use of the plugin
- Jira URL: enter the full URL of the Jira instance to connect with (make sure to include any custom port numbers). Entering this URL into a web browser should bring up the Jira login page and is typically of the form:
https://mycompany.atlassian.net - Jira Login: enter a valid login to the Jira instance that has permissions to create and view Jira issues and versions. Typically this is your Atlassian email address.
- Jira API Key: enter the API Key (not password) for the Atlassian login you are using
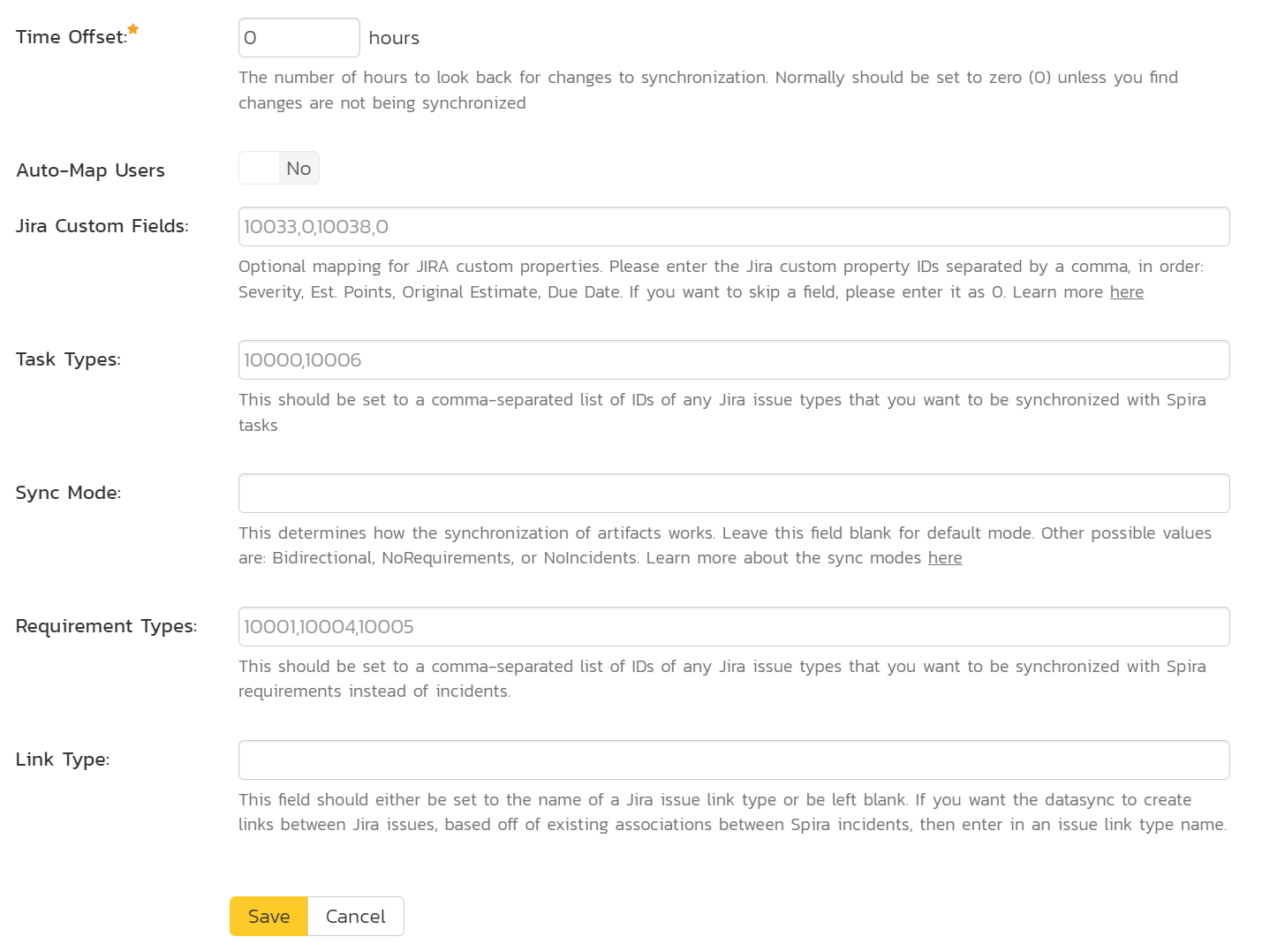
- Time Offset: is used to synchronize the clocks between Spira and Jira. The data-synchronization plug-in relies on exact date-time stamps to detect when issues or comments have been updated. If the timezones of the two servers do not match, the synchronization may fail to pick up recent changes. To configure this correctly, you must use the Spira's time zone as your baseline reference.
How to calculate the Time Offset value
Calculate the difference in hours between Jira and Spira, and enter it using the following rules:
- If Jira timezone is BEHIND Spira: Enter a positive number (Example: If Jira's server time is 2 hours behind Spira, enter 2)
- If Jira timezone is AHEAD OF Spira: Enter a negative number (Example: If Jira's server time is 2 hours ahead of Spira, enter -2)
- If both servers are in the same timezone: Leave this set to 0.
Note: Please check your Spira and Jira server configurations to determine the exact time difference in hours, ensuring you enter accurate information into this field.
- Auto-Map Users: This changes the way that the plugin maps users between Spira and Jira. Set to yes to auto-map users, or no to manually map users. See [below]
Configuration Tip
For most users, we recommend leaving "Jira Custom Fields" blank. If you want to sync Tasks and/or Requirements, do not forget to configure "Task Types" and/or "Requirement Types", and choose the proper "Sync Mode". Leave "Requirement Types" blank if you do not want to sync user stories/requirements (not valid for the NoIncidents mode).
- Jira Special Fields: This is used to specify the value(s) for Spira Incident Severity and/or Requirement Estimate Points based on Jira custom properties. Please enter the Jira custom property IDs separated by a comma. Both fields are optional, but if you want to skip one, please enter it as 0. Also, use this field to activate Time Tracking fields sync. This can be left empty for now and will be discussed below in Configuring Jira Special Fields.
- Task Types: This should be set to a comma-separated list of IDs of any Jira issue types that you want to be synchronized with Spira tasks instead of incidents. If you leave this blank, tasks in Spira will not be synced with Jira at all.
-
Sync Mode: This determines how the synchronization works. How each mode works is explained above:
- Default (leave blank): recommended for most users.
- Bidirectional: enter the word "Bidirectional" to use this mode. Recommended for advanced users only. Only use this mode if you have a well-defined set of workflows that make sense in both systems, and that do not conflict. If using this mode make the polling interval as short as possible (to avoid conflicting changes in the two systems) as the integration works at the record-level, not the field level.
- Complete: enter the word "Complete" to use this mode. Recommended for advanced users only. Like the bidirectional sync mode, only use this mode if you have a well-defined set of workflows that make sense in both systems, for all artifacts, and make the polling interval as short as possible, to avoid conflicting changes in the two systems. This mode syncs all the artifacts bidirectionally, but you can also use the field Types to Skip to ignore the sync of some Jira types.
- NoRequirements: enter the word "NoRequirements" to use this mode
- NoIncidents: enter the word "NoIncidents" to use this mode
Optionally, you can enter extra parameters to modify the standard behavior of any sync mode. These parameters are added after the sync mode, separated by commas:
- NoAttachments: Prevents syncing of file attachments between systems
- createReleasesOnly: Creates new releases/versions but never updates existing ones (useful to prevent the plugin from modifying your Jira versions)
Examples:
Bidirectional,NoAttachmentsComplete,NoAttachments,createReleasesOnlyDefault,NoAttachments(or justNoAttachmentsfor default mode) -
Requirement Types: This should be set to a comma-separated list of IDs of any Jira issue types that you want to be synchronized with Spira requirements instead of incidents. If you leave this blank, all Jira issue types will be synchronized with incidents (user stories/epics will not be synced at all). This field is ignored when using the sync mode "noIncidents", as Requirements are the main artifact of this mode.
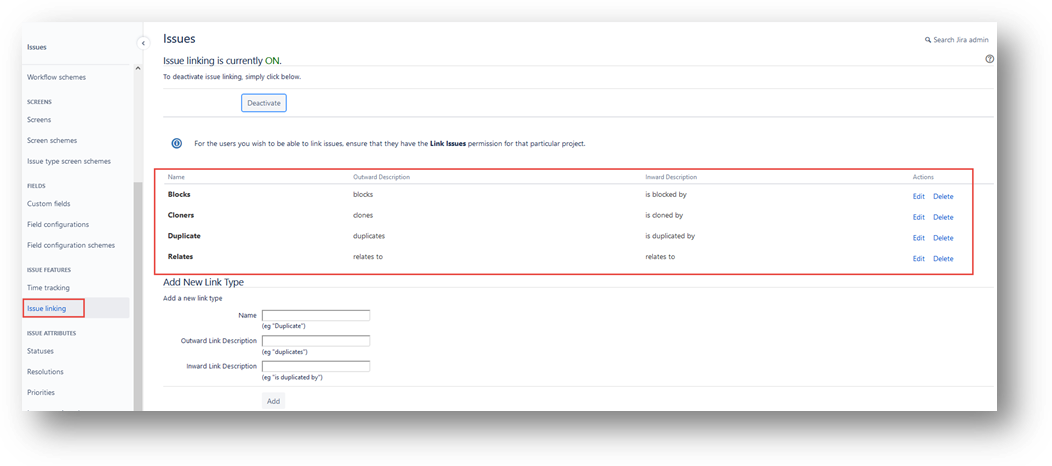
- Link Type: This field should either be set to a single name of a Jira issue link type or be left blank. If you want the datasync to create links between Jira issues, based on existing associations between Spira incidents and/or requirements, then enter in an issue link type name. If you do not want Jira to create these links between issues based on data in Spira, then leave this field blank. The artifact associations from Spira will sync to Jira as links of that type. All the link types from Jira will sync to Spira as 'Related-to'. You can get the list of issue link types from the following screen in Jira:
- Types to Skip: This optional field can be used to ignore some Jira issue types during the sync. To do this, enter a comma-separated list of IDs of any Jira issue types that you want to exclude from synchronization. If you leave this blank, all Jira issue types will be considered for synchronization, sync mode permitting.
- Skip Comments: Set this field to Yes if you want the dataSync to ignore comments in both directions. Please note old comments already synced won't be deleted.
- Auto-Map Properties: Set this field to Yes if you want the dataSync to try to automatically map the standard and custom properties based on name matching. When enabled, the system will automatically map properties with matching names between Spira and Jira, significantly reducing the need for manual mapping. Even if this option is enabled, you can still manually map properties as explained in this documentation. The system will try to auto-map only the blank mappings. Learn more here.
Configuration Tip
If you are using the Auto-Map Properties option, please remember you still need to activate the sync for your project and provide an External Key as explained below. The auto-mapping will occur when the datasync runs for the first time after activation, but you won't see the values on the mapping pages, so you can still provide different values for manual mapping.
- Sync Epic/Story hierarchy: Set this field to Yes if you want to see the Epic/Story hierarchy reflected in Spira Requirements and vice-versa, depending on the sync mode.
Hierarchy Limitations
Spira supports multi-level Requirement hierarchies that are more complex than Jira's default capabilities. The dataSync plugin cannot create hierarchical relationships in Jira that aren't supported by its configuration. When encountering an unsupported hierarchy structure, the dataSync will place the affected work item at the root level instead. To customize your work item hierarchy settings in Jira, please refer to the Jira documentation.
- Use Plain Text: Set this field to Yes to remove any formatting from the description fields when using either the bidirectional or the complete sync modes. This allows the description fields to sync bidirectionally (two ways) depending on the sync mode. This option is useful if you don't require complex text formatting.
Rich Text vs Plain Text
If you normally don't add text formatting, embedded images, or files to your descriptions and need updated text to be visible in both systems, use Plain Text. However, if you need embedded images, colors, tables, etc., in your descriptions, use Rich Text. Please note that Jira has limited capabilities for exporting and importing text formatting. Consequently, while the plugin will do its best to sync the text, some differences in formatting may occur. Also, due to these limitations, when using Rich Text sync, changes to description fields are only synchronized one-way - from the source artifact (older) to the target (newer) and never in the reverse direction. By default, the plugin will add a warning message to the affected description fields to remind you of this limitation. Alternatively, you can skip adding these warnings and use a custom property to indicate that instead. See the 'Skip Rich Text Warnings' field below.
- Skip Rich Text Warnings: Set this field to Yes to prevent the plugin from adding warning messages to description fields when using Rich Text sync. By default, when Rich Text sync is enabled, the plugin adds a warning message to description fields that cannot be updated bidirectionally. Enabling this option removes those warnings, giving you cleaner descriptions. However, you should only enable this if you understand that description changes will only sync one-way (from older to newer artifacts). You can use custom properties in Spira and Jira to indicate which is the oldest counterpart if you choose to skip the warnings. Learn more below.
Setting Up the IsOlder Property (Recommended when Skip Rich Text Warnings is enabled)
When you enable Skip Rich Text Warnings, you need to configure the "isOlder" property so users can identify which system contains the original version of each artifact. This property indicates whether an artifact was created first in Spira or Jira, helping users know where they can safely edit descriptions.
Why you need this property:
When Rich Text Warnings are disabled, users won't see warning messages in description fields. The isOlder property becomes essential because it tells users which system is authoritative for each artifact's description. Users should only edit descriptions in the system where isOlder = true to ensure their changes sync properly.
Setup Steps:
-
In Spira - Create a custom property:
- Go to Administration > [Artifact Type]* > Custom Properties
- Create a new custom property:
- Set the Type to Boolean
- Give it any name that makes sense to your team, e.g.: "Is Older", "Original System", "Descriptions are Updated?", etc.
-
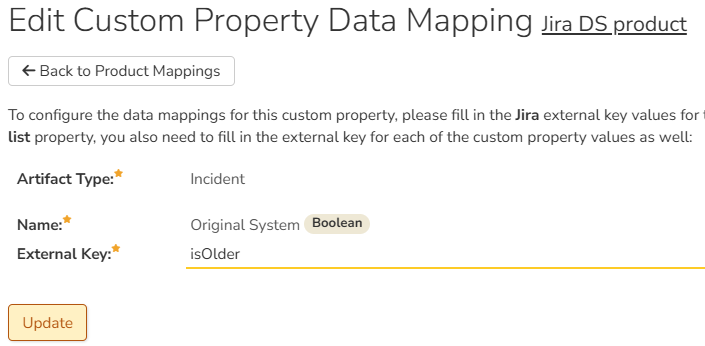
In Spira - Map the property:
- Go to the product's Jira datasync mapping page
- Click on the custom property you just created
- Set the External Key to exactly isOlder
- Click "Save"
*Repeat steps 1 and 2 for Incidents, Requirements, and/or Tasks, depending on what you need to sync.
- In Jira - Create a matching custom field:
- Go to Jira Settings > Issues > Custom fields
- Create a new custom field of type Radio Buttons
- Add exactly two options*: Yes and No (Jira doesn't support boolean fields natively)
- Important: Name this field with the exact same name you used in Spira (e.g., "Original System")
- Associate it with the appropriate issue types (Bug, Story, Task, etc.)
- Add it to the relevant screens so users can see it
*Or, alternatively, Oui/Non (French), Sí/No (Spanish), Sim/Não (Portuguese), or Ja/Nein (German)
How it works:
- When an artifact is created in Spira and synced to Jira: isOlder = true in Spira, false in Jira
- When an artifact is created in Jira and synced to Spira: isOlder = false in Spira, true in Jira
- Users should only edit descriptions where isOlder = true to ensure changes sync properly
- The plugin automatically maintains these values during synchronization
Example scenario:
- A bug is reported in Spira (isOlder = true in Spira, false in Jira)
- The bug syncs to Jira
- If you update the description in Spira, it will sync to Jira
- If you update the description in Jira, it will NOT sync back to Spira
- This prevents conflicts and ensures the source system remains authoritative for descriptions
User Mapping¶
The datasync does not create users itself. Instead, it maps existing users in Spira to existing users in Jira, where it can. These mappings mean that the datasync will correctly show who is, for example, assigned to an incident, if that field was updated from Jira during the datasync.
Note: Note: Even with full user mapping configured, synchronizing comment author names is limited by the Jira API. This is due to restrictions within the Jira API, which does not allow an external system to post comments on behalf of another user.
User mapping has two different modes: auto-mapping users; and manual user mapping.
Set the "auto-map" field described above to yes to use auto-mapping. In this mode, all users in Spira need to have the same username as users in Jira. This is a big time-saver but only works if you can guarantee that all usernames are the same in both systems.
If you are not auto mapping users (the field is set to no in the plugin configuration) follow these steps:
- Login as a system admin
- Go to Administration > Users > View Edit Users to show the list of users
-
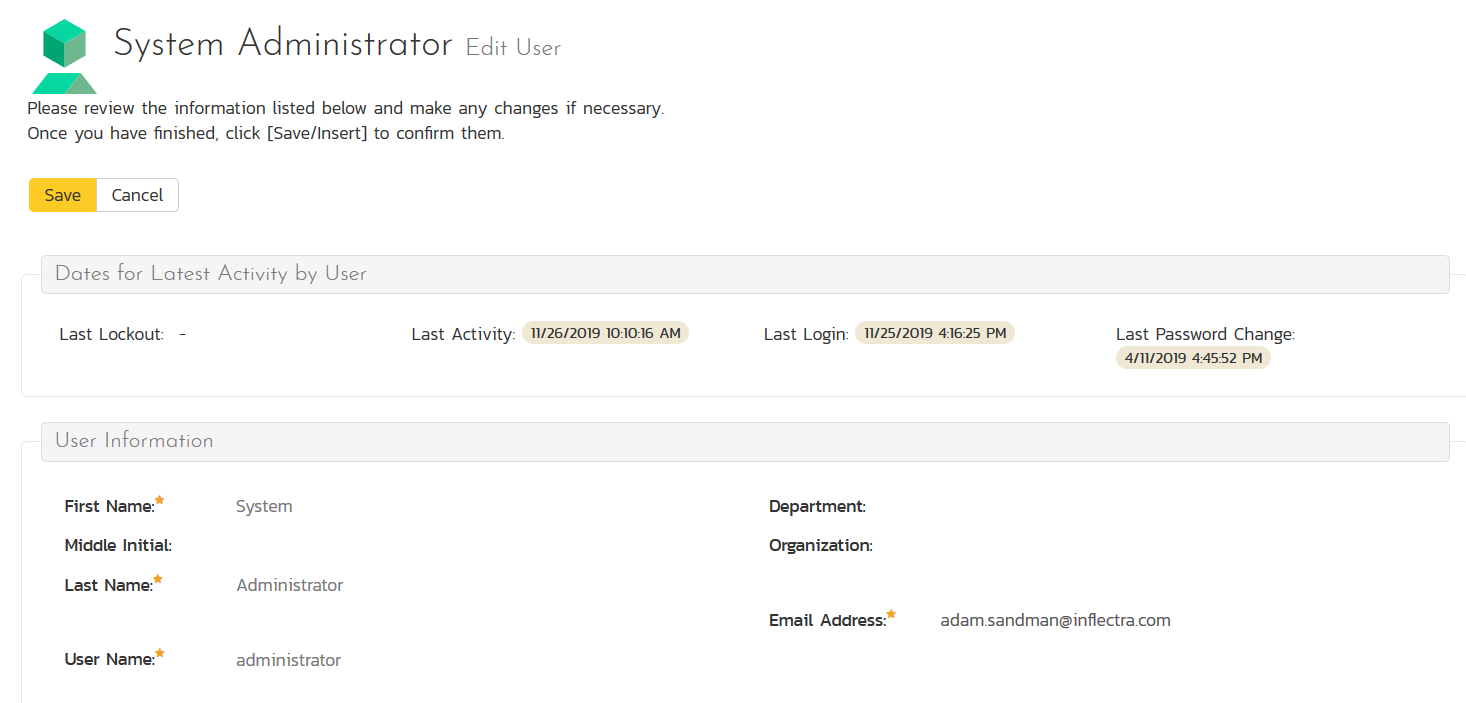
For each user you want to manually map to a Jira user:
- Click the "Edit" on that user's row:
- Click the "Data Mapping" tab at the bottom to see the list of datasync plugins you can set for this user.
- Enter a valid Jira identifier for that user in the text box called "Jira ID" (see below)
- Click "Save"

Valid Jira user identifiers
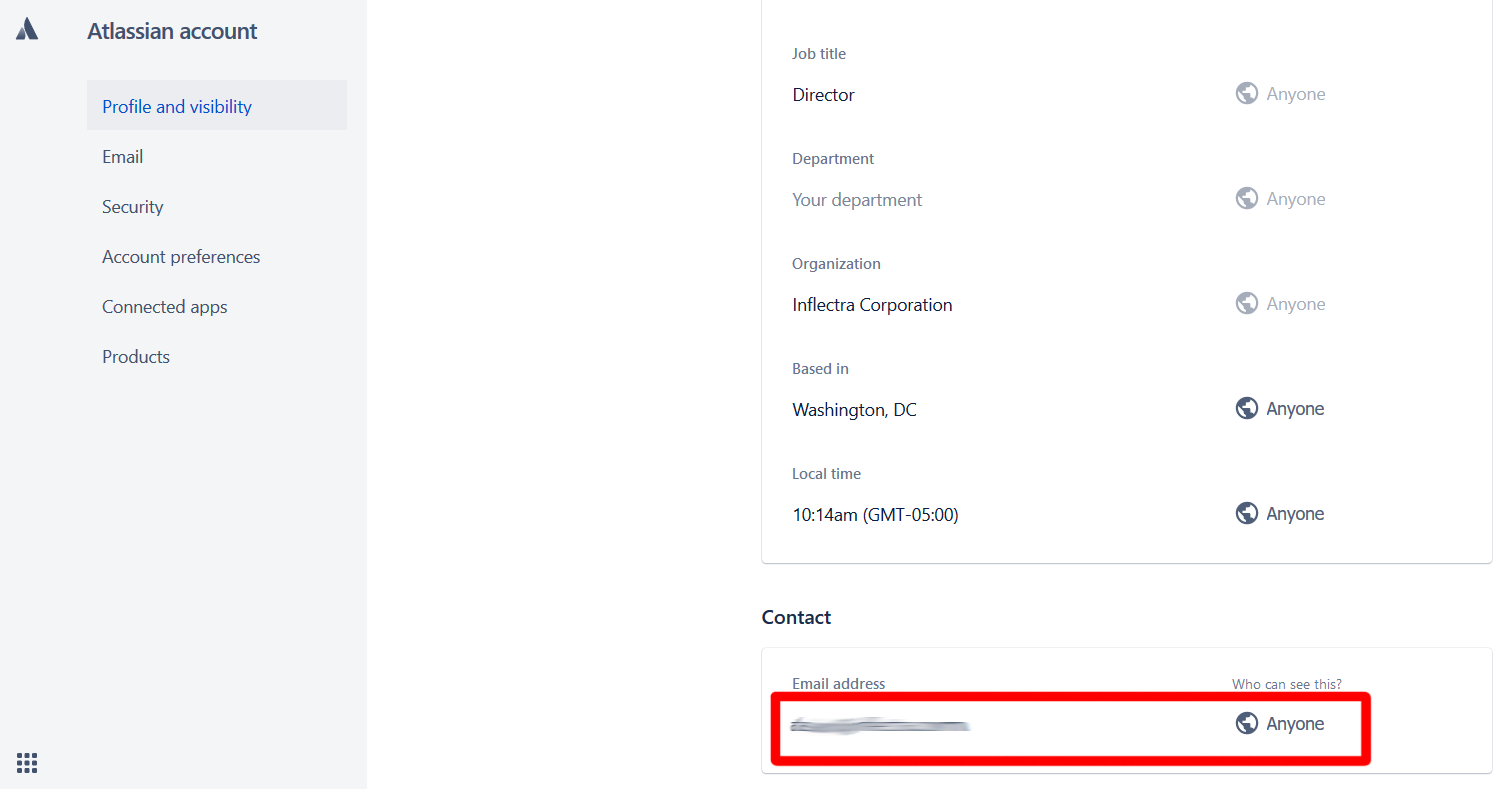
Email Address: use the email address of the user as it is used in Jira. This will only work if the user's profile is set to public and that the profile's email address visibility set to Anyone in Jira:
Atlassian AccountID: you can always use this value - it does not matter if the user's profile is public or private.

Product Configuration¶
Now that the datasync and user mapping have been set up system-wide, you are ready to configure the datasync at the product level. This is an important and necessary part of the process. It tells the datasync what products to sync with, what to sync it with in Jira, and how to sync up all the different fields.
How to copy datasync configuration to another product
Once you have successfully configured the product for the datasync, you can clone the datasync configuration. When creating a new product, make sure to choose the option to "Create product from Existing product" rather than "Use Default Template" so that all the product mappings get copied across to the new product.
Jira Configuration Helper¶
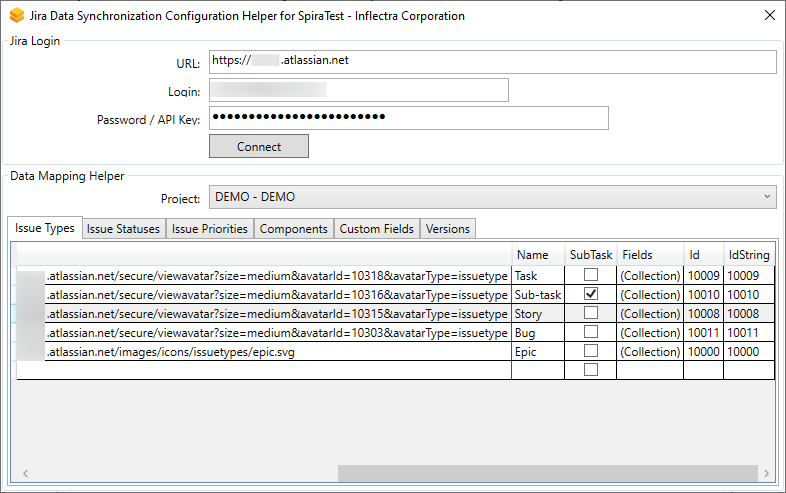
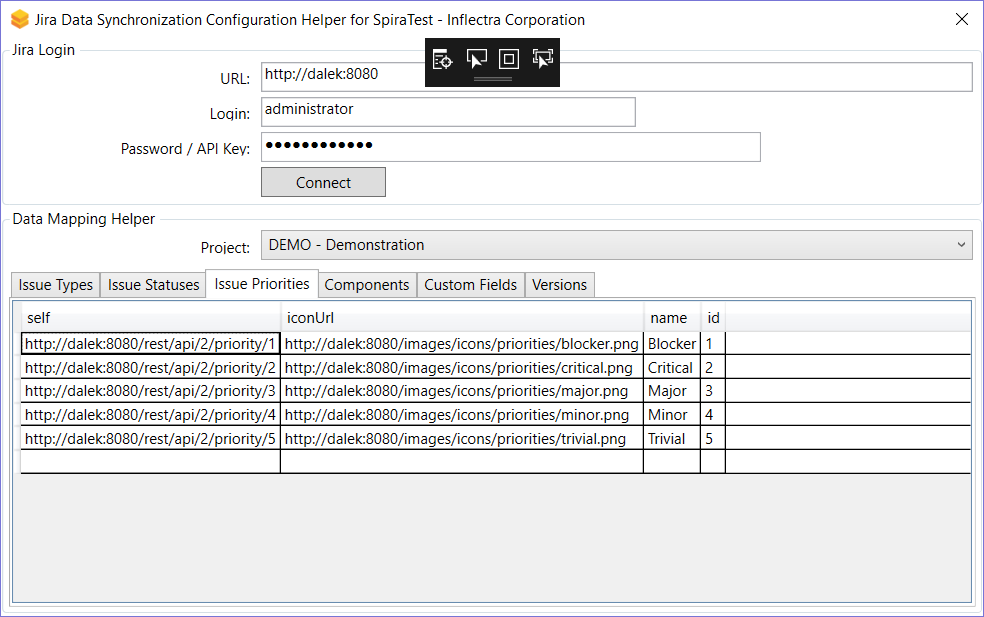
It is difficult to find the unique IDs for various fields and items in Jira from the web application. To make the product configuration and all the required data mapping easier, please use our helper application. This is a Windows application that connects to your Jira instance (cloud or on premise) and helps you find the IDs for all various fields in Jira.
- Download the helper here.
- Unzip the contents
- Run the JiraConfigurationHelper.exe. You will see the screen below:
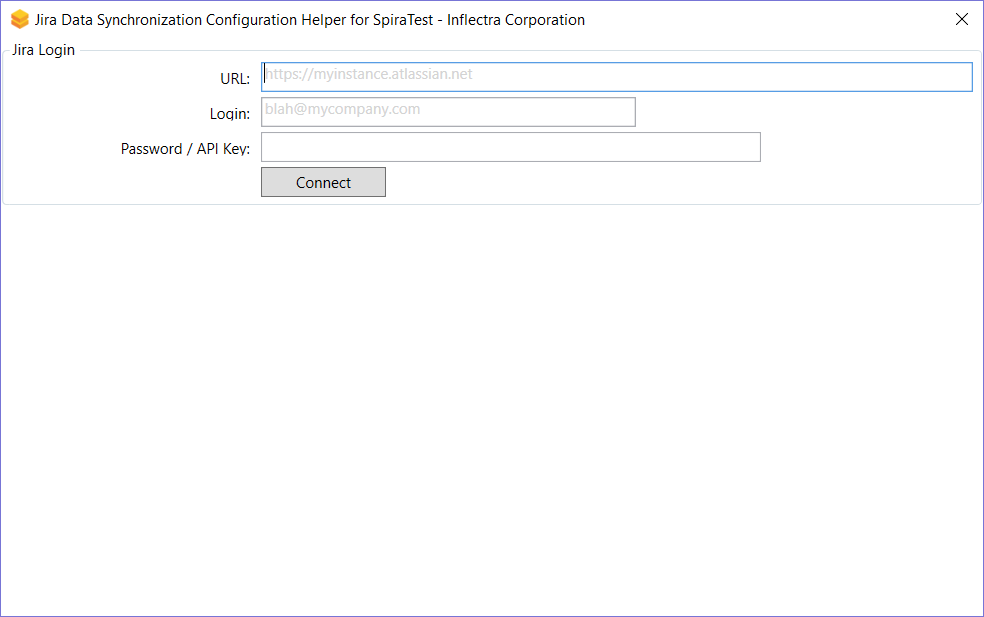
- Enter in the URL of your Jira instance, along with a login and API Key (as describe above)
- Click "Connect"
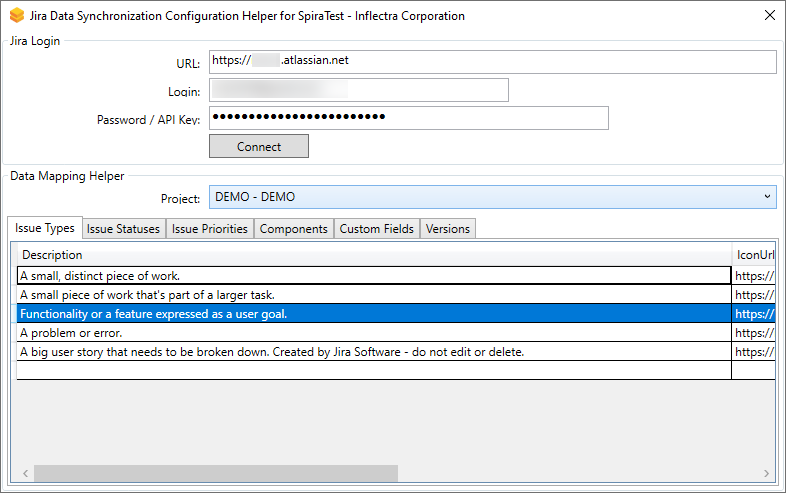
- Choose the project in Jira you want to get IDs for
You will then see tabs for the following information: issue types, issue statuses, issue priorities, components, versions, and custom fields.
Keep the helper application open so you can refer to it as you go through the remaining configuration steps below
Activate the datasync¶
- Login to Spira as a system administrator
- Go to System Administration > Integrations > Data Synchronization
- Open the "Data Mapping" dropdown for the plugin and select the product you want to sync with
- Click the arrow to the right of the product name
- This will open the Jira data-mapping home page for the selected product:
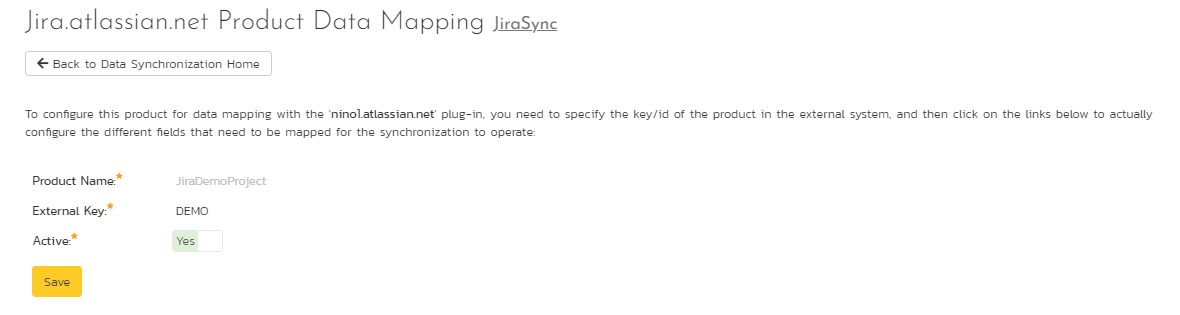
If the project name does not match the name of the project you want to configure the data-mapping for, click on the "(Change Project)" hyperlink to change the current product.
To activate this product for the datasync, update the following fields:
- External Key: enter the short acronym name of the project in Jira
- Active: set to 'Yes' to activate the datasync for this product. Remember to set this back to "No" to turn off the datasync when the product or need for sync has finished
- Click "Save"

Note: One Spira product can only be mapped to one Jira project, in other words it is a one-to-one mapping only.
Pausing Data Synchronization
If you need to pause the synchronization for any reason, existing Jira ID field values in Spira are preserved. To ensure that the mapped Jira IDs remain visible and correctly linked within the Spira artifacts (such as Requirements):
- Do not delete the JiraDataSync Plugin from the Data Synchronization list pages.
- To pause synchronization, simply set the DataSync to inactive for the specific product (as explained in a section above).
- Once synchronization is restarted, all previously mapped Jira IDs will remain intact and correctly linked.
Supported Artifacts¶
Supported Artifacts for Jira Synchronization
Because Spira's Artifact Field Mapping page displays all possible fields universally, please use the matrix below to understand which artifacts are actively supported by the Jira integration.
| Spira Artifact | Jira Support Status | Jira Equivalent Item |
|---|---|---|
| Requirements | ✅ Supported | Epics, Stories |
| Incidents | ✅ Supported | Bugs |
| Tasks | ✅ Supported | Tasks, Subtasks |
| Test Cases | ❌ Not Supported | N/A |
| Releases | ✅ Supported | Versions / Releases |
| Risks | ❌ Not Supported | N/A |
Note: If using SpiraTest, you do not need to setup the mappings for Tasks, as Tasks are not available in SpiraTest.
Release Mapping¶
The datasync uses a special mapping field to identify what a Spira artifact should sync with in Jira. It uses this field to map a Spira releases to a Jira version so that users can create releases/versions in one application and see them in either application. The summary of how it works is:
- valid mapping on a Spira release for a Jira version: no action
-
no valid mapping:
- datasync sees a Jira version for the first time: creates a new release in Spira (mapped to the Jira version)
- datasync sees a Spira release for the first time: creates a new version in Jira (with the Jira version then mapped to the Spira release)
Manual release mapping
To ensure your existing releases in Spira and Jira synchronize correctly, you should manually map them together before running the DataSync for the first time. As an extra benefit, performing this initial mapping prevents the integration from accidentally creating duplicate releases.
Here are step-by-Step mapping instructions:
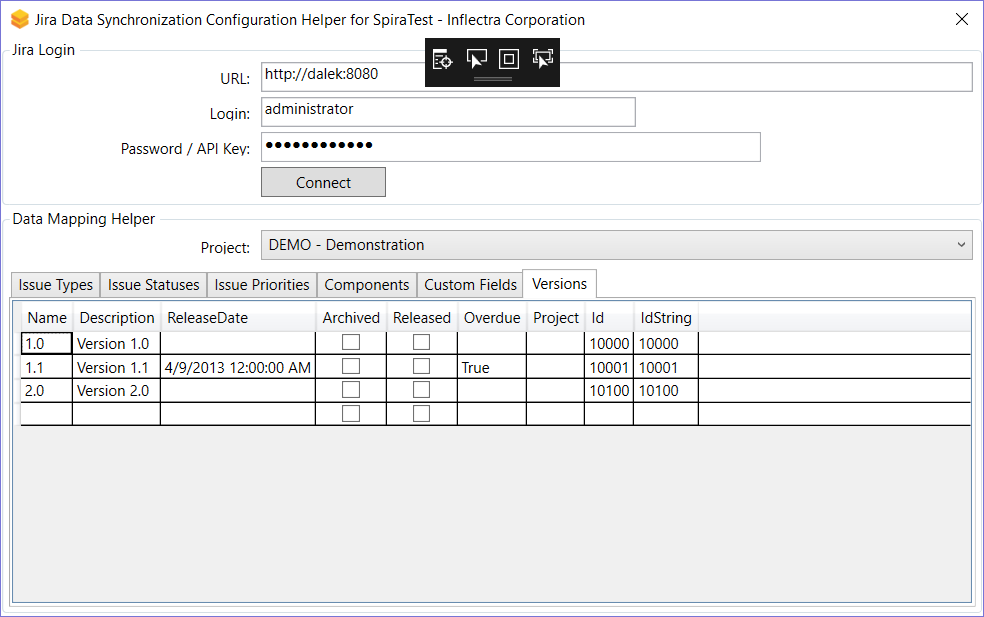
- Open the Jira configuration helper and switch to the Versions tab;
- Go to the product in Spira the release belongs to;
- Open the Release list page and locate the release you need map;
- Go to the overview tab of that release;
- Look for the field called JiraID (used to store the identifier of the equivalent version in Jira);
- Set the value to the Jira version ID gathered from the configuration helper tool;
- Click "Save".
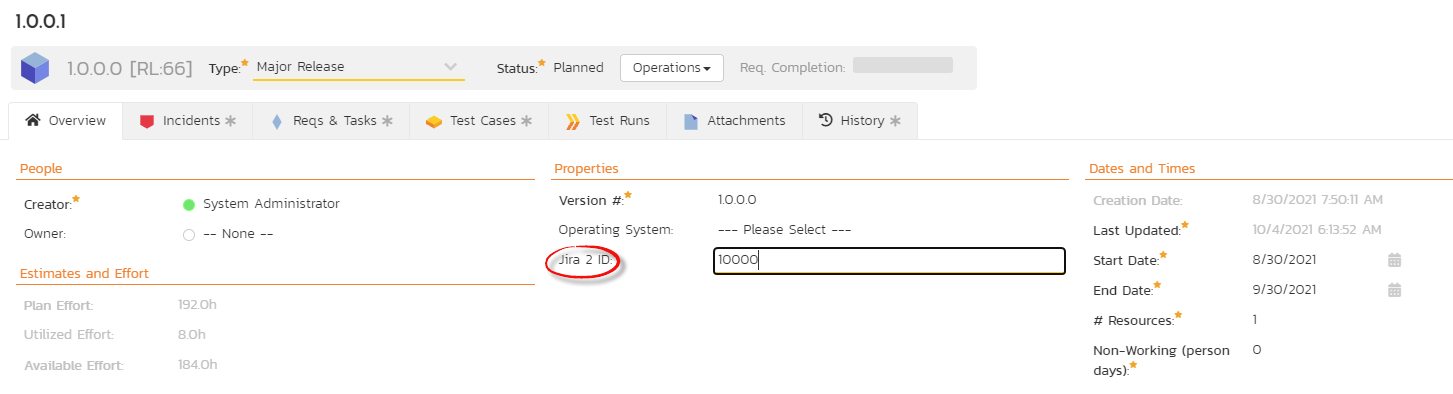
How to find the Jira version ID
The Jira ID for a version can be found using the Jira Configuration Helper on the Versions tab.
Note: When you have a blank Spira product, the datasync will create all needed releases in Spira, mapped to the corresponding Jira version.
Release synchronization behavior specific for datasync version
Spira releases/sprints and Jira versions/sprints are functionally different items by design 1. Furthermore, the way the integration handles their synchronization depends on your DataSync plugin version, upon newer capabilities being introduced:
For DataSync v8.0 and Later: Releases synchronize bidirectionally and automatically. There is no need to manually associate a release with a specific artifact for the sync to trigger. For DataSync Pre-v8.0: Releases will only synchronize if they are actively assigned to an item. The field mappings behave as follows:
| Artifact Type | Spira Field | Jira Field |
|---|---|---|
| Bug / Incident | Detected Release | Affects Version |
| Bug / Incident | Resolved Release | Fix Version |
| Requirement | Release | Fix Version |
Standard Field Data Mapping¶
You can use Auto-Map to simplify and potentially skip the manual mapping process described in this section.
Mapping field values between Spira and Jira is a very important part of the configuration. Without this step, the datasync will not know what values to match things up with. For example, it will not know that an Jira issue with a type of "New Feature" should become an incident in Spira with a type of "Enhancement"
This process starts on data mapping home page for the selected product you were on to activate the datasync. On this page you will see a large list of options like in the screenshot below. This shows different fields across different artifacts.
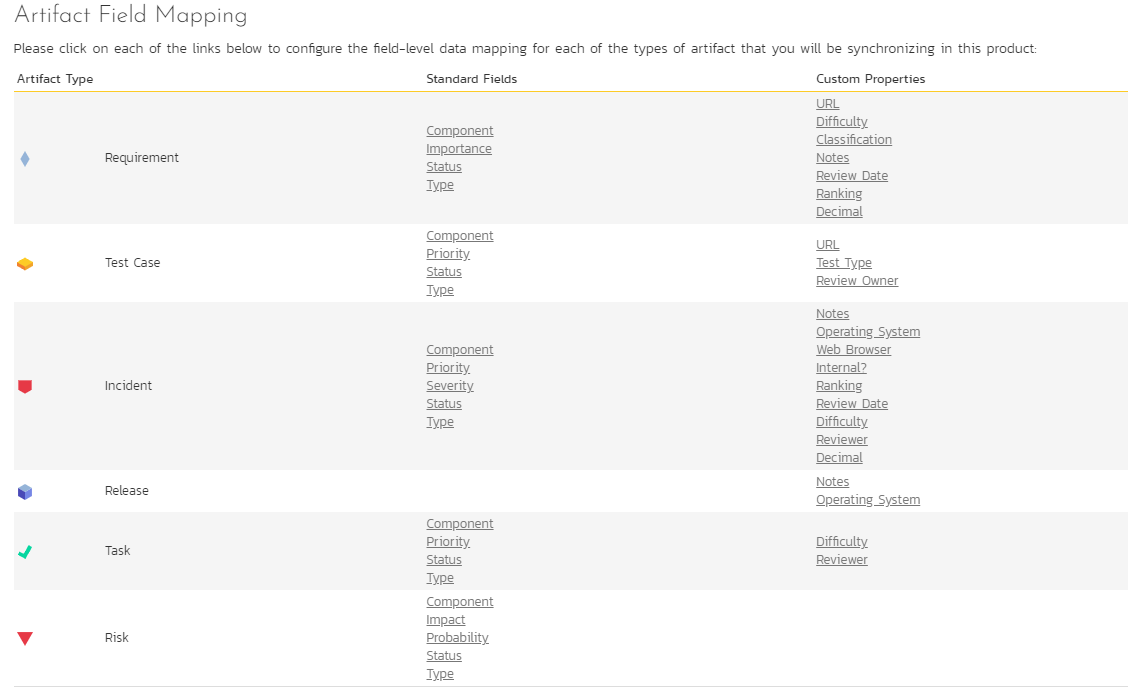
Not all fields and artifacts need to be mapped
The screenshot above shows all possible artifacts and fields that any of our datasyncs use. Only some of these are need to be filled in for each particular datasync. So, only fill in mappings for fields explained below that meet your needs.
For many of the fields, you can map multiple Spira field values to the same Jira field value (e.g. Bug and Incident in Spira may both map to Bug in Jira). If you map the same Jira ID for different Spira field values, make sure to set "Primary" to Yes on one of the field values. This will be the value used when syncing from Jira to Spira.
Incidents¶
If not using Auto-Map, this field mapping is required
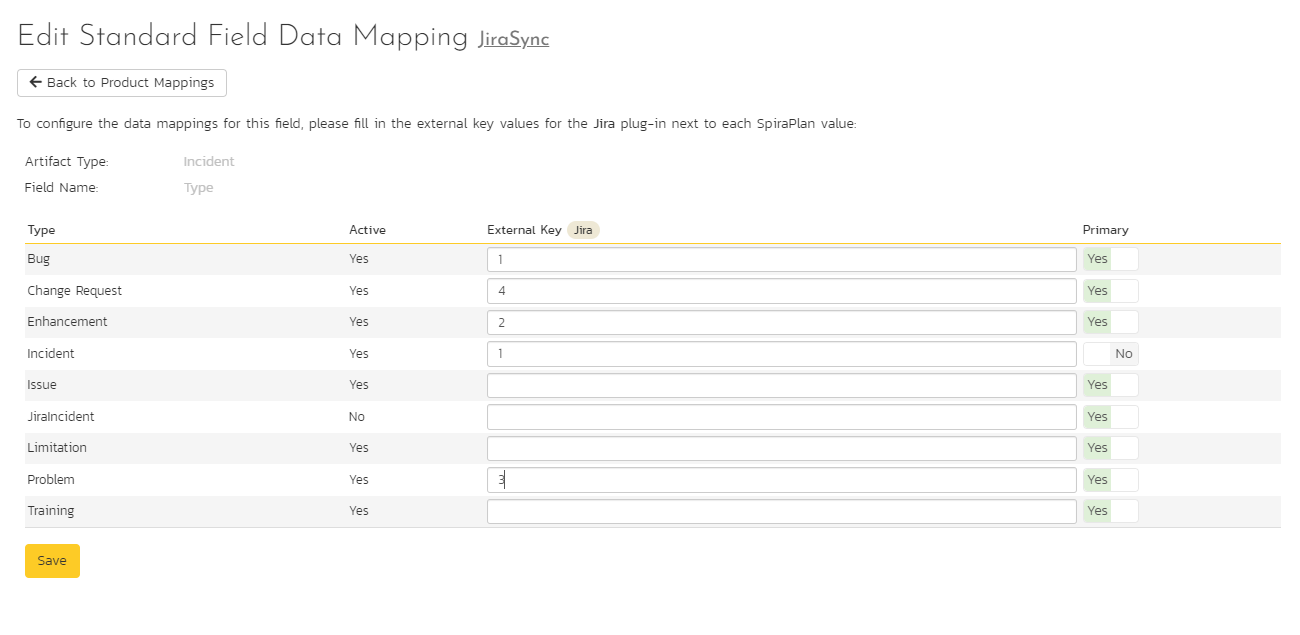
Click on the "Type" hyperlink under Incident Standard Fields to bring up the Incident type mapping configuration screen. The table lists each of the incident types available in Spira. Enter the matching Jira issue type ID for each one.
The Jira ID can be found by using the "Issue Types" tab of the Jira configuration helper.
If not using Auto-Map, this field mapping is required
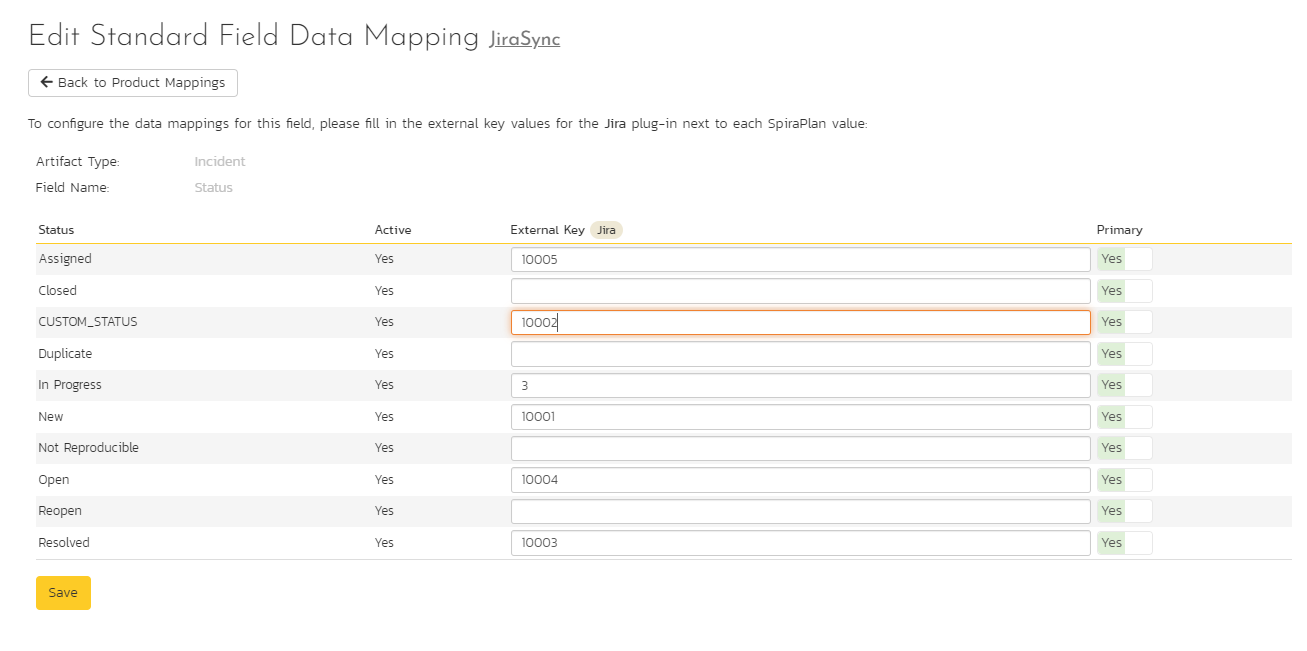
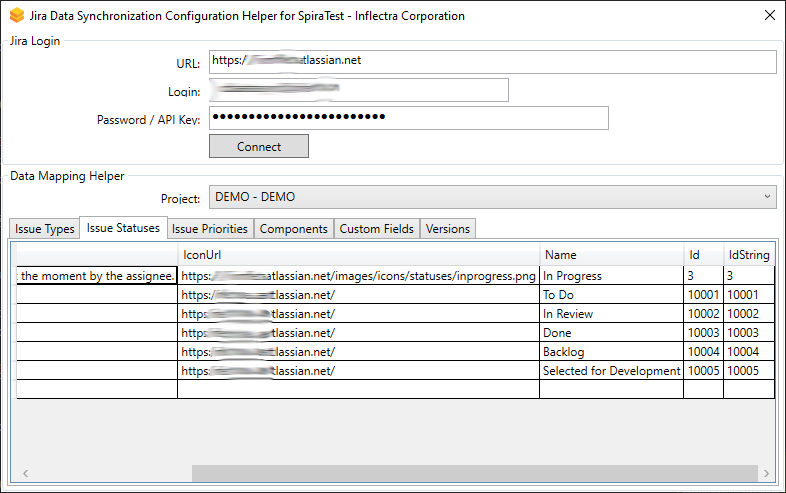
Click on the "Status" hyperlink under Incident Standard Fields to bring up the Incident status mapping configuration screen. The table lists each of the incident statuses available in Spira and provides you with the ability to enter the matching Jira issue status ID for each one.
We recommend that you map the New and Open Spira statuses to the Jira ID for "Open" and make the Spira status of Open the primary status. This means that when new incidents in Spira get synced over to Jira, they will get switched to the Open status in Jira which will then be synched back to "Open" in Spira. This helps you easily see which incidents have been synced with Jira and those that haven't.
The Jira ID can be found by using the "Issue Statuses" tab of the Jira configuration helper.
If not using Auto-Map, this field mapping is required
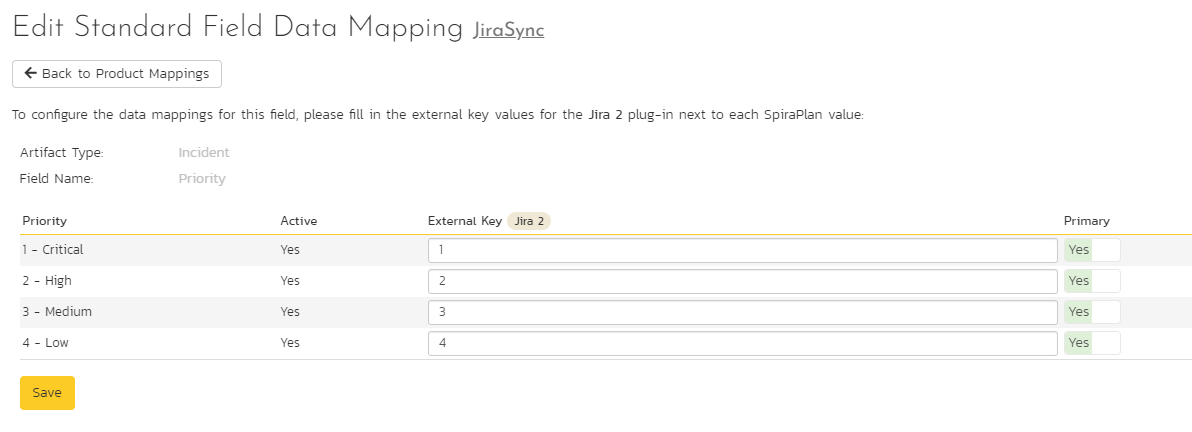
Click on the "Priority" hyperlink under Incident Standard Fields to bring up the Incident Priority mapping configuration screen. The table lists each of the incident priorities available in Spira and provides you with the ability to enter the matching Jira priority ID for each one.
The Jira ID can be found by using the "Issue Priorities" tab of the Jira configuration helper.
This field mapping is OPTIONAL. You can save time using Auto-Map.
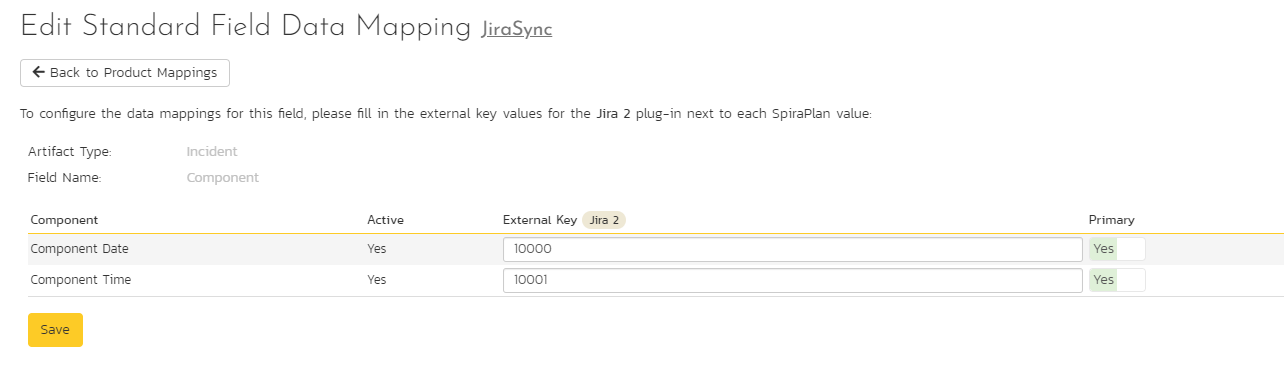
Click on the "Component" hyperlink under Incident Standard Fields to bring up the Incident component mapping configuration screen. The table lists each of the components available in Spira and provides you with the ability to enter the matching Jira component ID for each one.
The Jira ID can be found by using the "Components" tab of the Jira configuration helper.
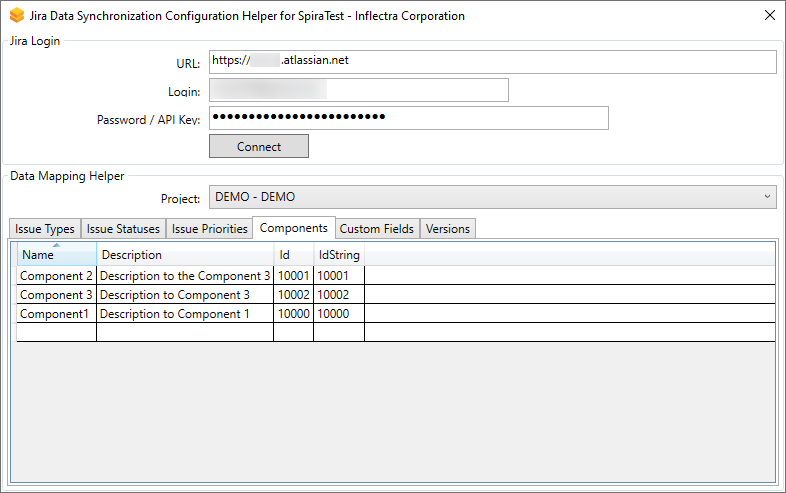
This field mapping is OPTIONAL.
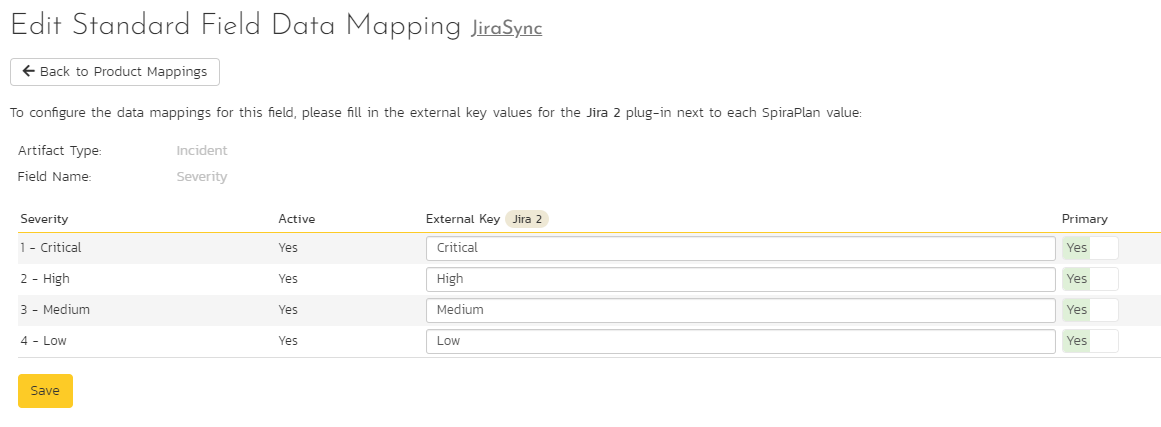
Click on the "Severity" hyperlink under Incident Standard Fields to bring up the Incident severity mapping configuration screen. Unlike the other incident standard fields, Jira doesn't have a built-in severity field. If you want to see Spira incident severities in Jira, create a Jira custom list field to store the different severity values. If you don't want to synchronize severity values with Jira, you can skip the rest of this section.
Once you have created a severity custom list field in Jira, you need to: - populate the field mappings with the name (not the ID) of the severity custom property values in Jira - go to the Plugin configuration screen - Enter the ID of the custom field you're using to store severities in Jira in the "Jira Custom Fields" field. You can find the ID on the "Custom Fields" tab of the Jira configuration helper.
Requirements¶
This field mapping is required if syncing requirements. You can save time using Auto-Map.
If you are not syncing requirements you can skip this section
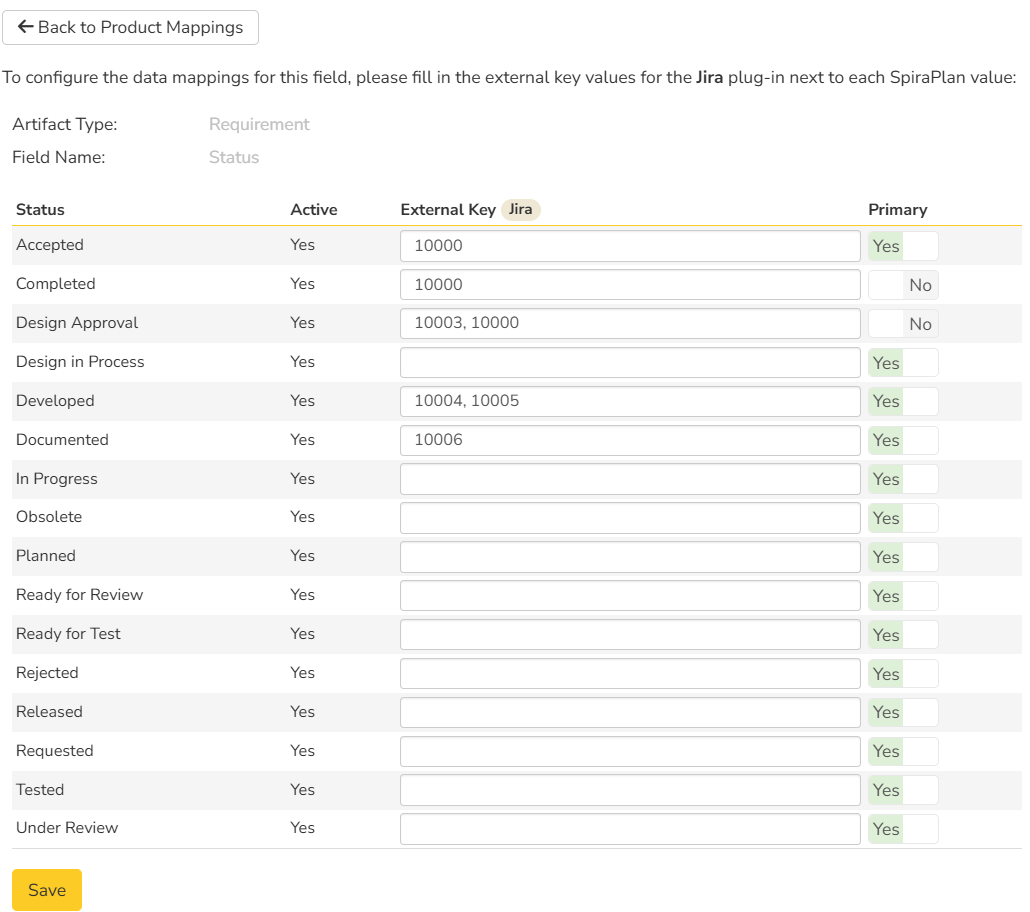
Click on the "Status" hyperlink under Requirement Standard Fields to bring up the Requirement status mapping configuration screen. The table lists each of the requirement statuses available in Spira and provides you with the ability to enter the matching Jira issue status ID for each one.
This mapping optionally supports more than one Jira status per row; just enter a comma-separated list of Jira statuses. Please make sure to not mark duplicated fields as Primary.
The Jira ID can be found by using the "Issue Statuses" tab of the Jira configuration helper.
This field mapping is optional if syncing requirements. You can save time using Auto-Map.
If you are not syncing requirements you can skip this section
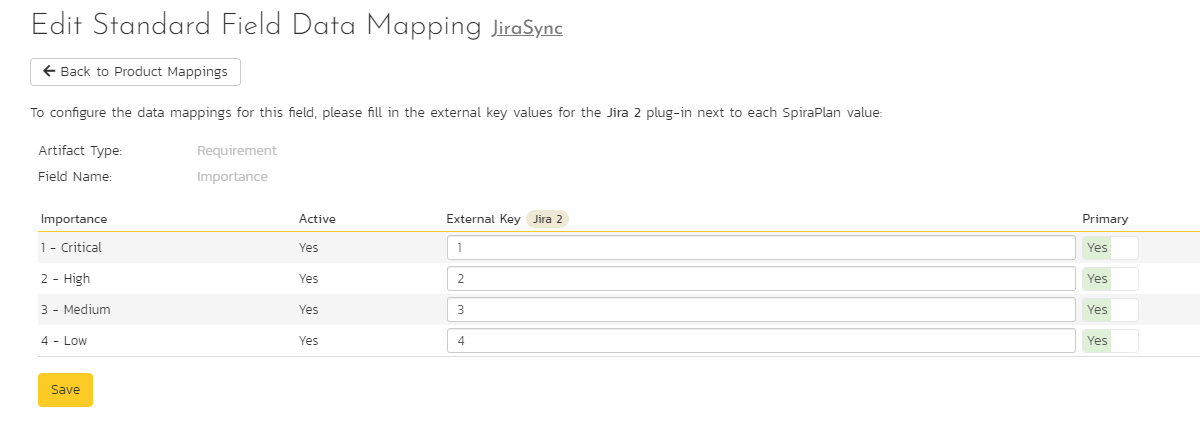
Click on the "Importance" hyperlink under Requirement Standard Fields to bring up the Requirement Importance mapping configuration screen. The table lists each of the requirement importances available in Spira and provides you with the ability to enter the matching Jira priority ID for each one.
The Jira ID can be found by using the "Issue Priorities" tab of the Jira configuration helper.
This field mapping is required if syncing requirements. You can save time using Auto-Map.
If you are not syncing requirements you can skip this section
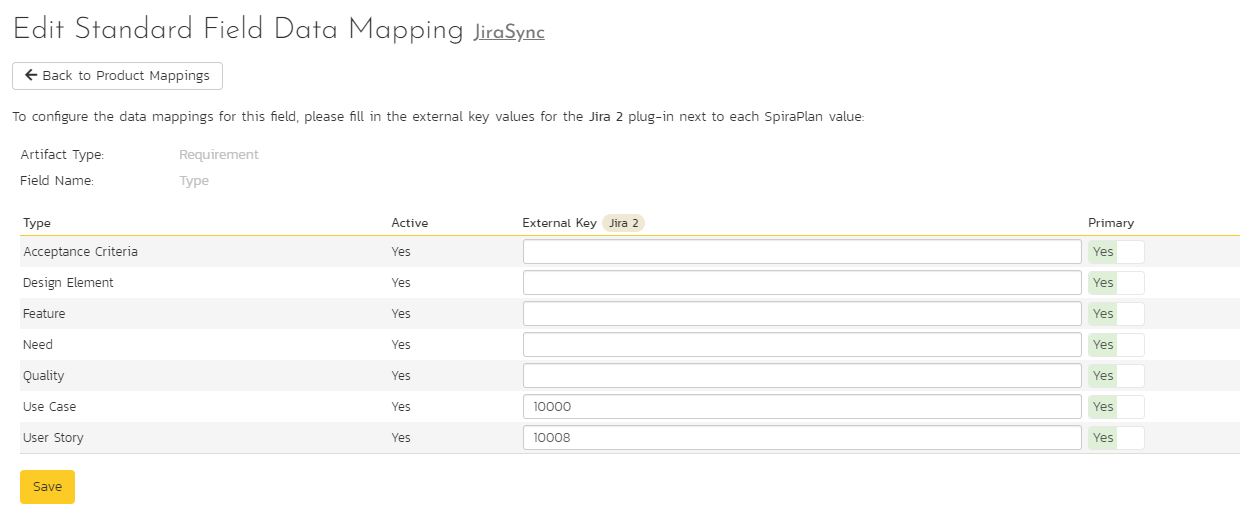
Click on the "Type" hyperlink under Requirement Standard Fields to bring up the Requirement type mapping configuration screen. The table lists each of the requirement types available in Spira and provides you with the ability to enter the matching Jira issue type ID for each one.
The Jira ID can be found by using the "Issue Types" tab of the Jira configuration helper.
This field mapping is optional if syncing requirements. You can save time using Auto-Map.
If you are not syncing requirements you can skip this section
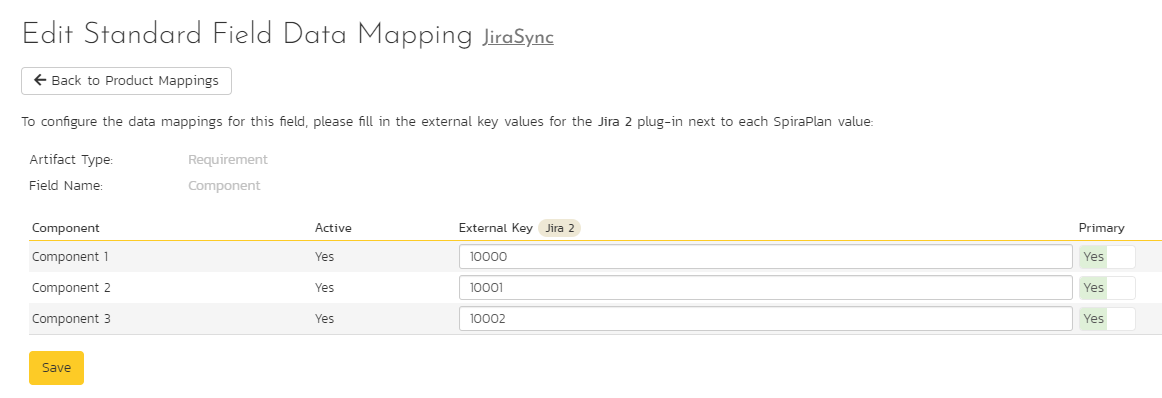
Click on the "Component" hyperlink under Requirement Standard Fields to bring up the Requirement component mapping configuration screen. The table lists each of the components available in Spira and provides you with the ability to enter the matching Jira component ID for each one.
The Jira ID can be found by using the "Components" tab of the Jira configuration helper.
This field mapping is optional if syncing requirements.
If you are not syncing requirements you can skip this section
To sync Estimate Points for Requirements in Spira, make sure you add Estimates to your Jira issues as "Story points" or have a numeric custom property in Jira to map against. Use the Jira configuration helper to find its ID (under the "Custom Fields" tab). Enter this ID in Spira, as the second attribute (after a comma ',') of the "Severity/Est. Points Field" on the Datasync configuration page. For example: '10001,10033' where 10001 is the Incident Severity property ID in Jira and 10033 is the field we are configuring, the Estimate Points property ID in Jira. Make sure this field was created as a numeric field in Jira, otherwise the sync won't happen.
This field mapping is optional if syncing requirements.
If you are not syncing requirements you can skip this section
To sync Due Date from Jira with Spira Requirements, create a custom property type Date for your Requirements in Spira and in the dataSync mappings, enter duedate as its external key. This field only syncs Jira to Spira.
Tasks¶
This field mapping is required if syncing tasks. You can save time using Auto-Map.
If you are not syncing tasks you can skip this section
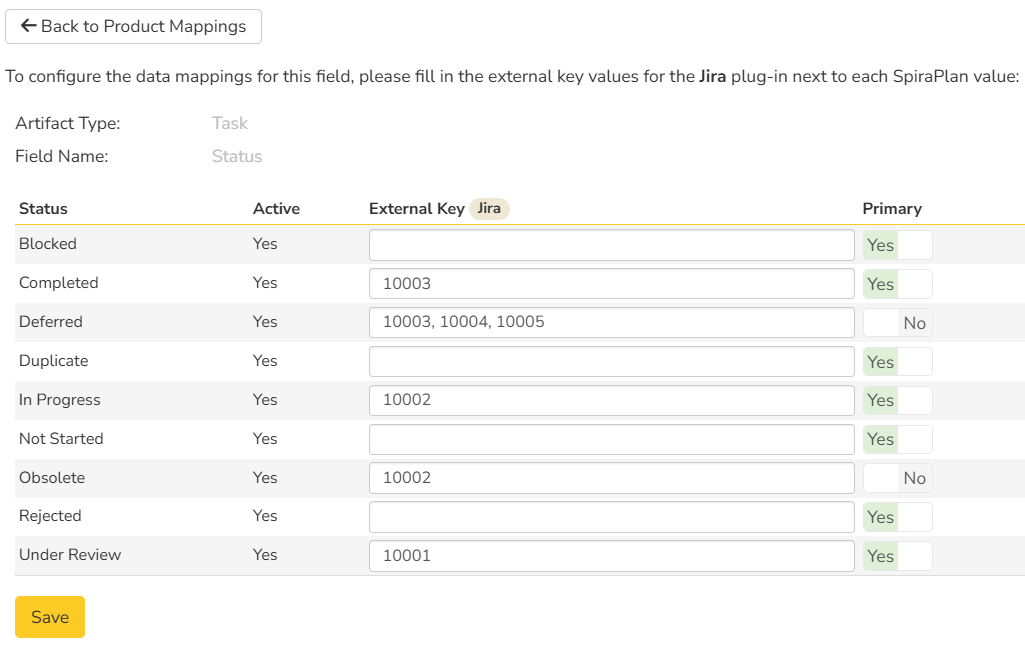
Click on the "Status" hyperlink under Task Standard Fields to bring up the Requirement status mapping configuration screen. The table lists each of the task statuses available in Spira and provides you with the ability to enter the matching Jira issue status ID for each one.
This mapping optionally supports more than one Jira status per row; just enter a comma-separated list of Jira statuses. Please make sure to not mark duplicated fields as Primary.
The Jira ID can be found by using the "Issue Statuses" tab of the Jira configuration helper.
This field mapping is optional if syncing tasks. You can save time using Auto-Map.
If you are not syncing tasks you can skip this section
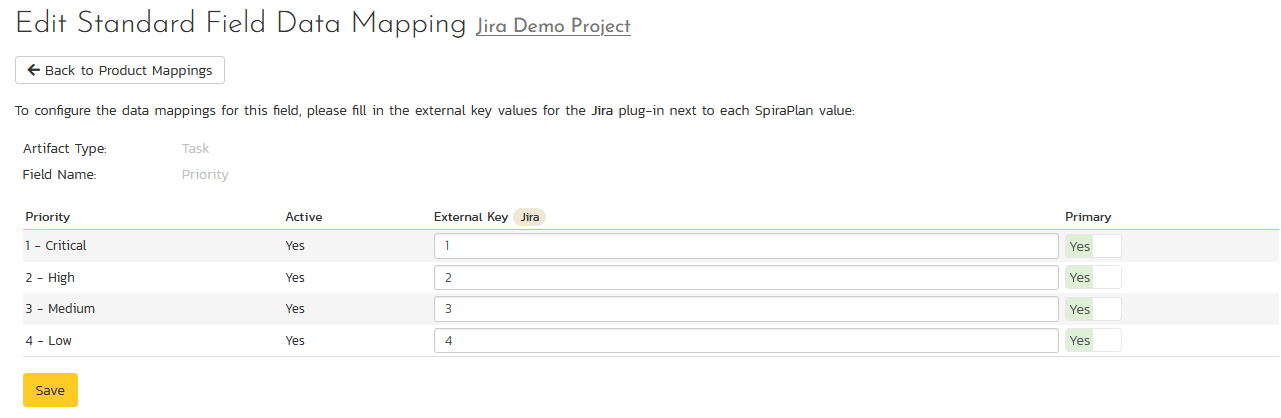
Click on the "Priority" hyperlink under Task Standard Fields to bring up the Task Priority mapping configuration screen. The table lists each of the task priorities available in Spira and provides you with the ability to enter the matching Jira priority ID for each one.
The Jira ID can be found by using the "Issue Priorities" tab of the Jira configuration helper.
This field mapping is optional if syncing tasks. You can save time using Auto-Map.
If you are not syncing tasks you can skip this section
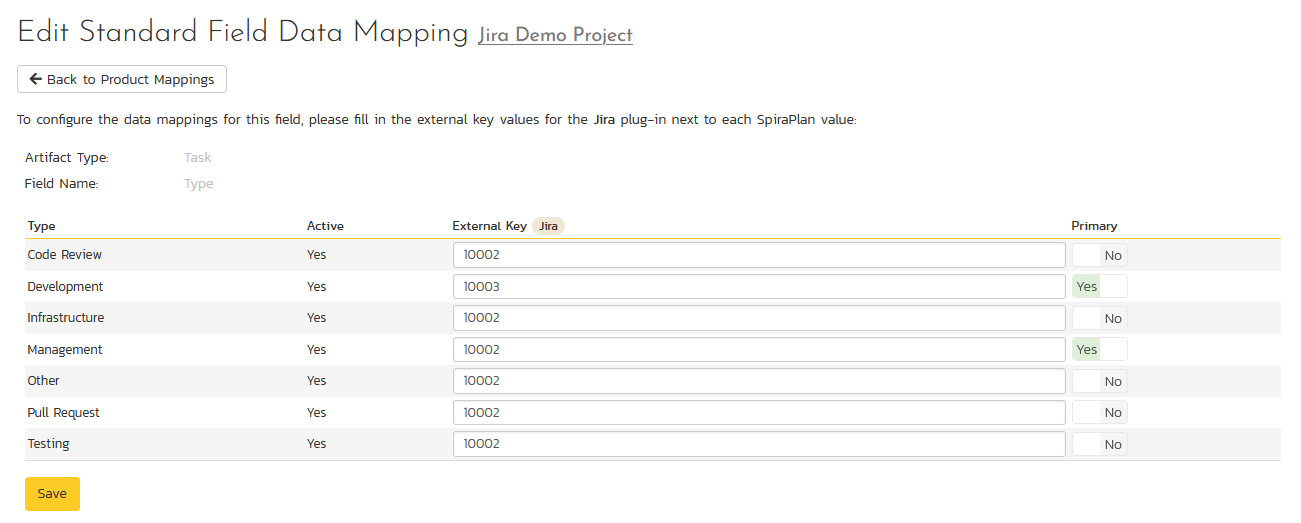
Click on the "Type" hyperlink under Task Standard Fields to bring up the Task type mapping configuration screen. The table lists each of the task types available in Spira and provides you with the ability to enter the matching Jira issue type ID for each one.
The Jira ID can be found by using the "Issue Types" tab of the Jira configuration helper.
Custom Property Mapping¶
You can use Auto-Map to simplify and potentially skip the manual mapping process described in this section.
You can map:
- custom properties in Spira to custom fields in Jira
- custom properties in Spira to standard fields in Jira (for example fields like Environment, Resolution, or SecurityLevel that don't exist in Spira)
You can save time using Auto-Map.
Custom Property types should exactly match in both applications
To ensure custom property mapping works properly and maintains a reliable bi-directional data flow, your data types must align precisely across both applications. Even minor differences in field types can cause synchronization failures.
-
Custom Field Type Compatibility: When mapping fields, ensure that the selected data types correspond exactly between systems. Use the table below as a guide for proper type alignment (Spira → Jira):
- Date → Date Picker - Cannot map to a DateTime field; types must match precisely.
- List → Select List (Single choice) - Used for picking a single option from a dropdown menu.
- Multiselect List → Select List (Multiple choices) - Used when a user needs to select multiple options.
- Text → Text (Short Text or Text Field) - Handles unformatted, plain text only.
- Release → Version picker (Single version) - Used to synchronize releases / versions.
- User → User Picker (Single user) - Must be set to 'User' on both sides to map system identities.
- Integer → Number - Used to synchronize only numeric data.
- Boolean → Checkbox - In case you need to get values like yes or no (0 or 1)
-
Standard Field Mapping Scope: As a general rule, Spira custom properties must be mapped exclusively to custom fields in your external application. Except for the specific native fields listed in the table below, there are no options to map standard system fields to custom properties.
- Severity (Allowed: Yes) — Requires a corresponding custom property to be manually created in Jira.
- DueDate native Jira field (Allowed: Yes) — For tasks and incidents: Spira's "Start Date" syncs natively to Jira's due date field. For requirements a corresponding custom property needs to be manually created in Spira.
- Resolution native Jira field (Allowed: Yes) — Requires a corresponding custom property to be manually created in Spira.
- Environment native Jira field (Allowed: Yes) — Requires a corresponding custom property to be manually created in Spira.
- Security Level native Jira field (Allowed: Yes) — Requires a corresponding custom property to be manually created in Spira.
- IssueKey native Jira field (Allowed: Yes) — Requires a corresponding custom property to be manually created in Spira.
- Component (Allowed: Yes) - Need to enter matching Jira component ID for each one, works for incidents and requirements.
- All Other Native Fields (Allowed: No) — You must use custom fields or properties, since DataSync basically does not recognize them.
To start, go to the data mapping home page for the selected product you were on to activate the datasync. Then click on the name of the custom property you want to add data-mapping information for. Below are the four different types of mapping that you can use
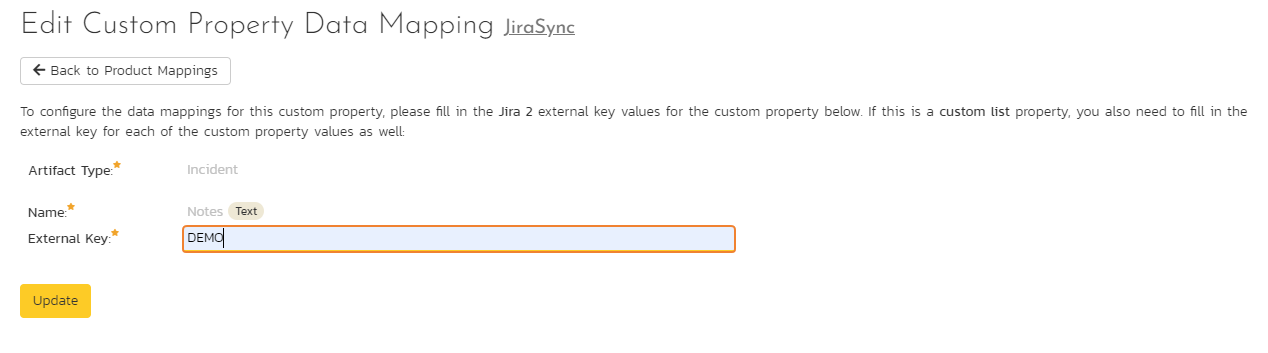
This refers to custom properties of all types except List and Multi-List. These properties have types like Text, Date, User, Release, Boolean, Decimal, Integer, and so on - as they have simple, user-entered values. For scalar custom properties, there will be no values listed in the lower half of the screen.
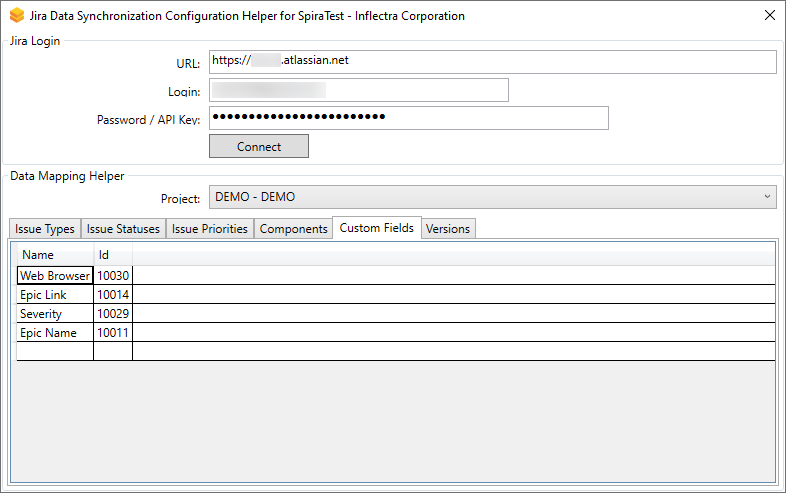
Fill in the "External Key" field with the Jira ID of the custom field and click "Save". The ID can be found by using the "Custom Fields" tab of the Jira configuration helper.
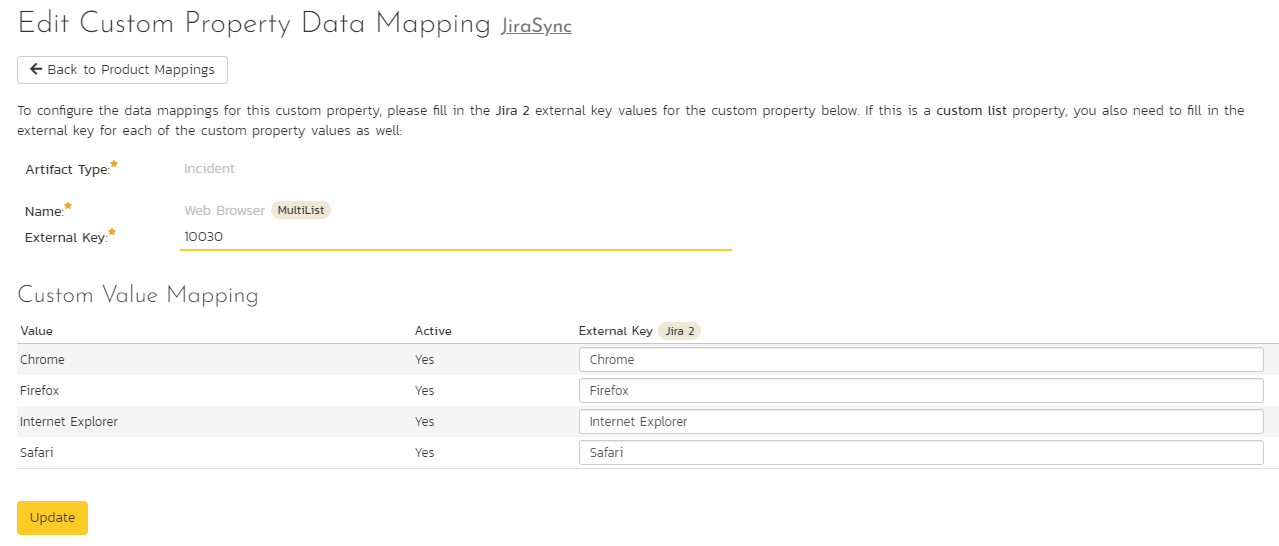
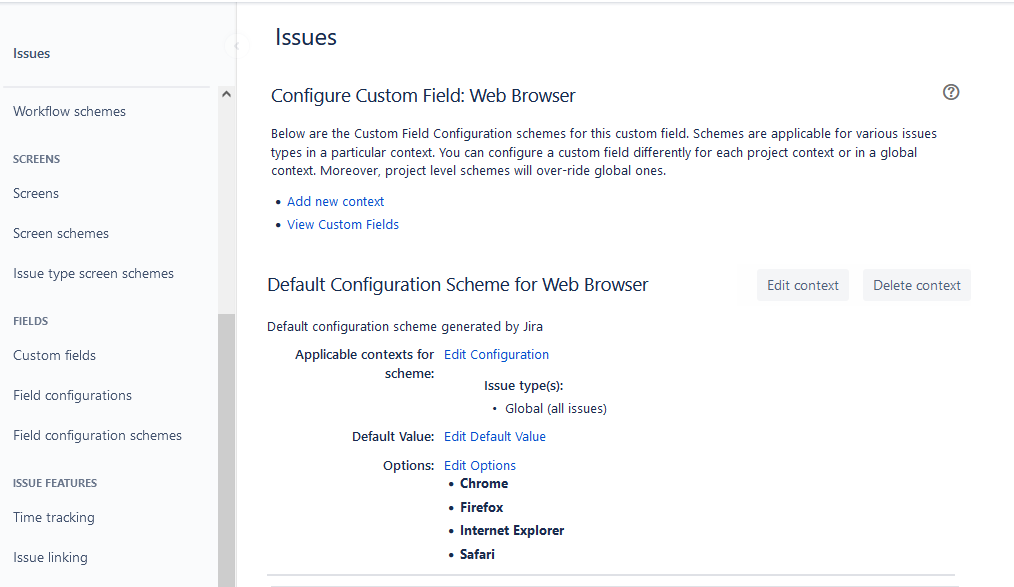
This refers to custom properties that are either of type List or Multi-List (in Jira called cascading, multiple choice, or single choice).
Fill in the "External Key" field with the Jira ID of the custom field. The ID can be found by using the "Custom Fields" tab of the Jira configuration helper.
For each of the property values on the lower half of the page, enter the full name (not the id) of the custom field value as specified in Jira:
Special Jira fields¶
If you would like the values of the Jira Resolution field to sync with Spira, work through these steps:
- create a custom list in Spira
- add the resolution names that exist in Jira as values in the list
- create an incident custom property of type List in Spira that uses the list you just created
- go to the product's Jira datasync configuration page (as used above)
- click on the hyperlink for the custom property you created
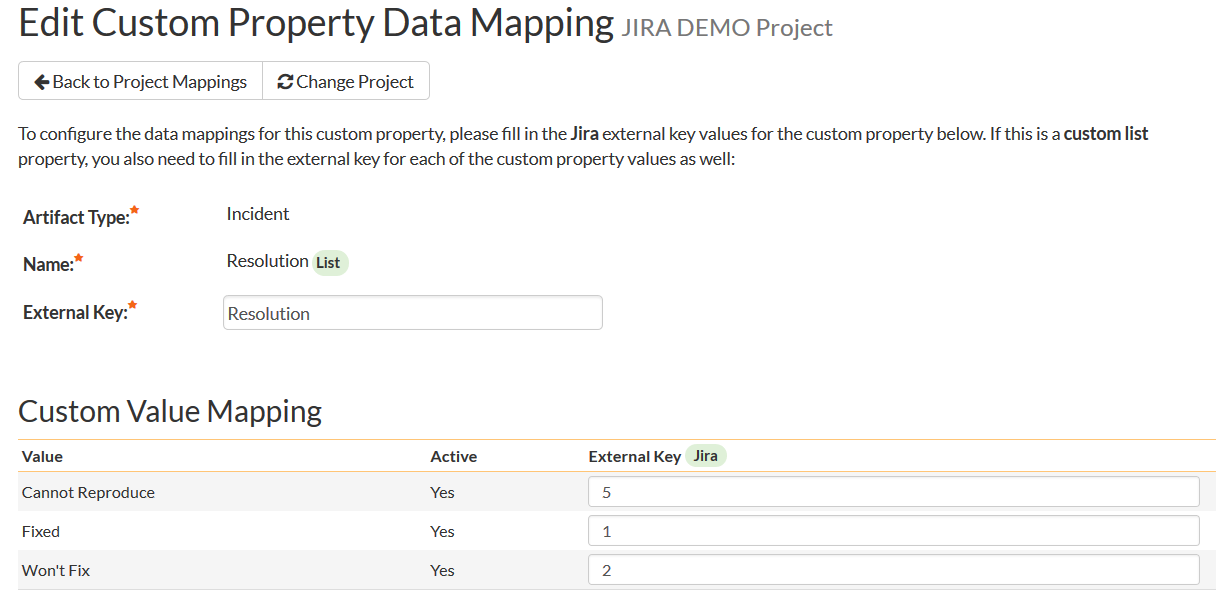
- enter "Resolution" as the External Key of the custom property
- for each of the property values in the table, enter the Jira ID of the various Resolutions that are configured in Jira
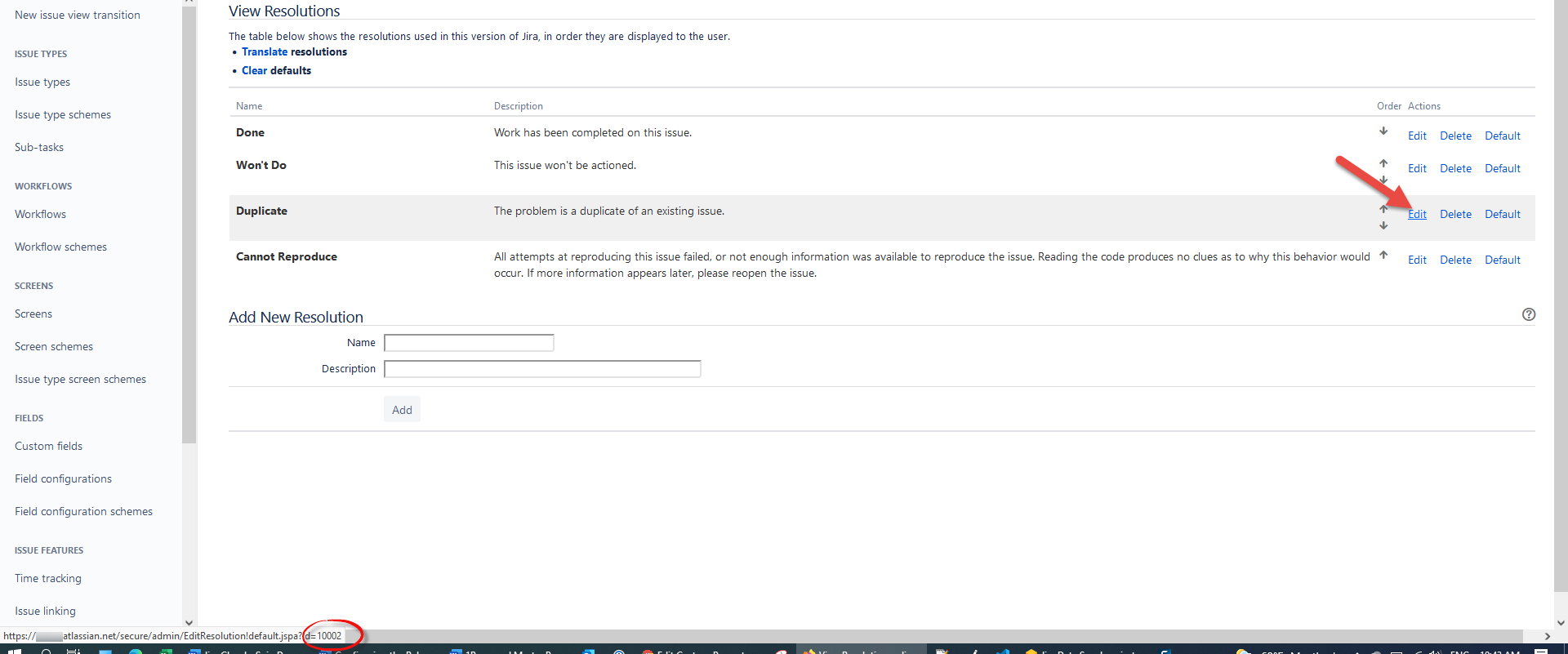
The external ID can be found by looking at the URL inside Jira when choosing to View/Edit the resolution name/description.
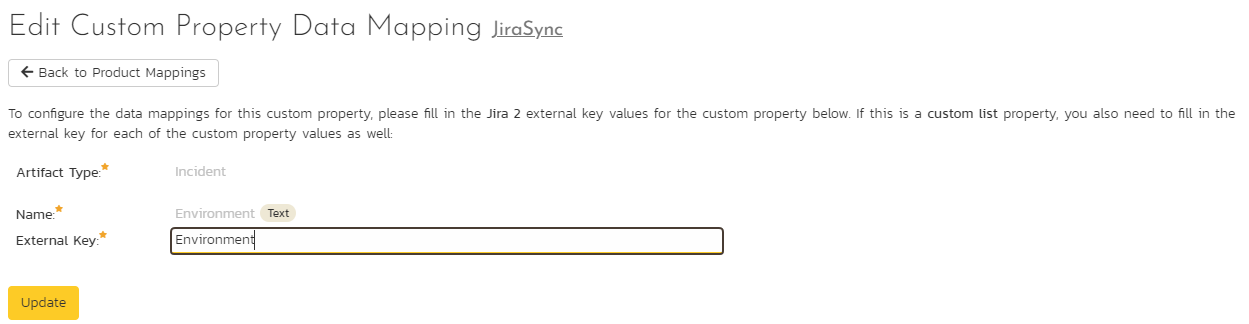
If your instance of Jira requires that all new issues are submitted with an "Environment" description, you need to fill out this section.
- create an incident custom property in Spira of type Text
- go to the product's Jira datasync configuration page (as used above)
- click on the hyperlink for the custom property you created
- enter "Environment**" as the External Key of the custom property
- click "Save"
If your instance of Jira requires that all new issues are submitted with a "Security Level" you need to fill out this section.
- create a custom list in Spira
- add the security level names that exist in Jira as values in the list
- create an incident custom property of type List in Spira that uses the list you just created
- go to the product's Jira datasync configuration page (as used above)
- click on the hyperlink for the custom property you created
- enter "SecurityLevel" as the External Key of the custom property
- for each of the property values in the table, enter the Jira ID of the various Security Levels that are configured in Jira

The external ID can be found by looking at the URL inside Jira when choosing to View/Edit the security level name/description.
Spira automatically stores the unique id of each Jira issue against the relevant Spira artifact. This field is visible on the artifact details page, in the "Properties" section. The field in Spira is named after the plugin name
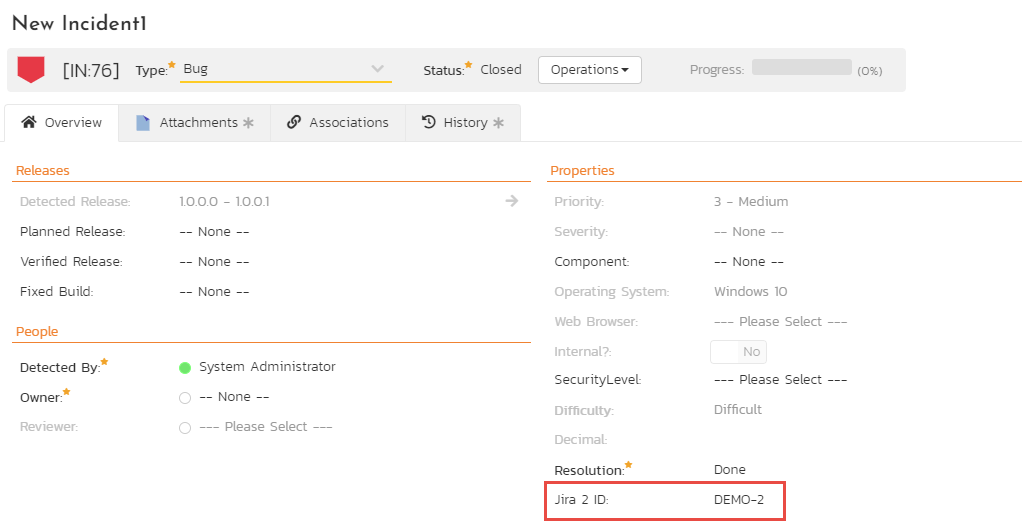
To also see the Jira ID on the Incident, Requirement, and/or Task list page(s):
- for each artifact (incident, requirement, and/or task) create a custom property in Spira of type Text
- go to the product's Jira datasync configuration page (as used above)
- for the given artifact, click on the hyperlink for the custom property you created
- enter "JiraIssueKey" as the External Key of the custom property
- click "Save"
If you would like to sync the Time Tracking values from Jira to Spira and vice-versa, please enter "timetracking" in the Jira Special Fields setting:

You also need to activate and configure this in Jira
In Jira, you need to enable Time Tracking in your project, as explained here. Once this is active for your project, you need to add the Time Tracking field to all the Issue types that sync against Spira artifacts, by going to:
- Settings > Projects
- In the left menu, Issues (Work Items) > Screens
- Then, for each Issue (Work Item) type you sync to Spira:
- Click on the pencil (edit)
- Then, for each Screen, click on its name
- Then, at the bottom of the page, select 'Time Tracking'
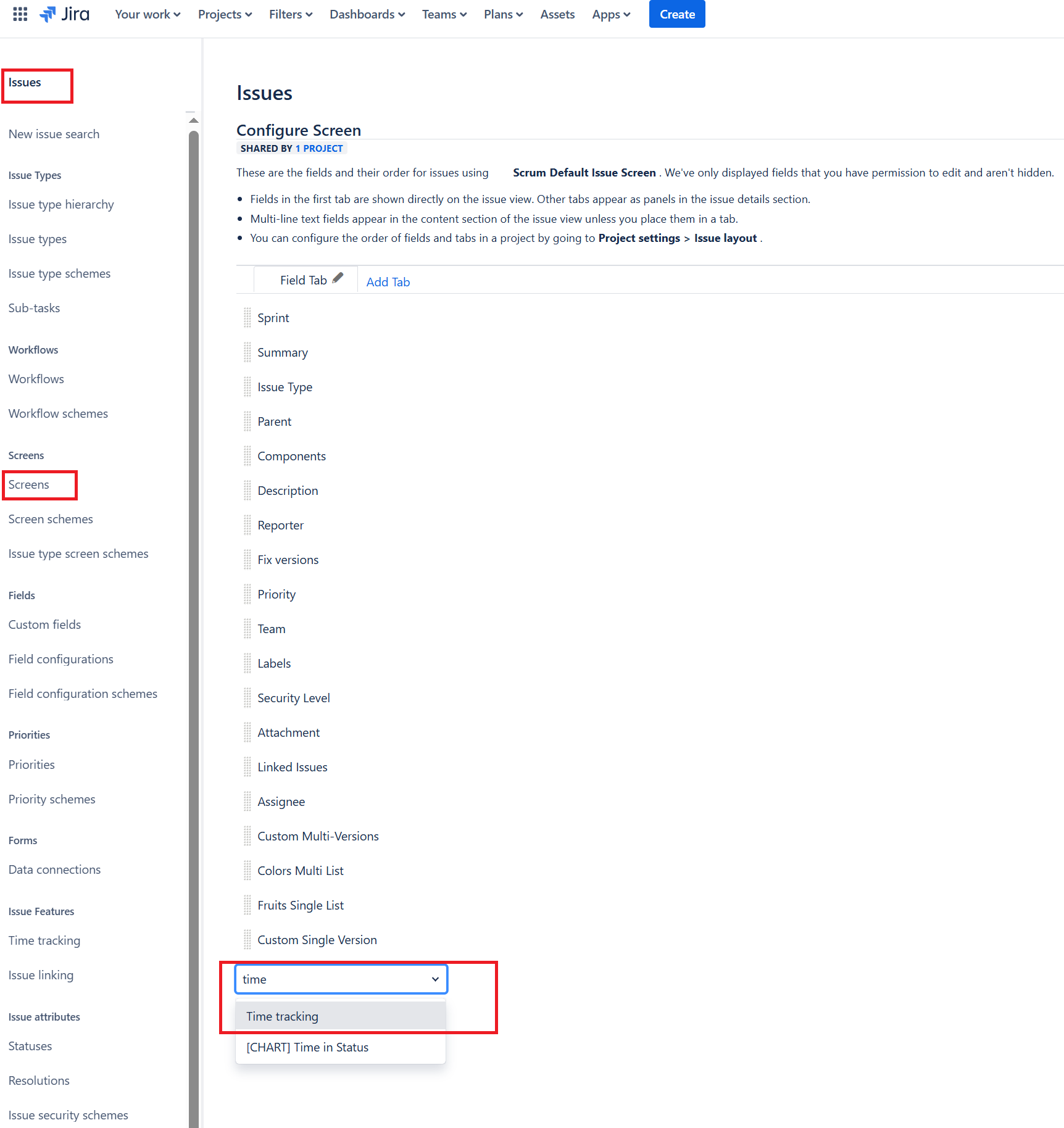
By following these instructions, you will see the fields syncing:
- Estimated Effort <=> Original Estimate
- Remaining Effort <=> Time Remaining
- Time Spent => Actual Effort
Please note Jira does not allow updates to the field 'Time Spent', so the plugin will ignore it when syncing Jira to Spira.
Using the Auto-Map Properties Feature¶
When the "Auto-Map Properties" option is enabled in the plugin configuration, the dataSync will attempt to automatically map standard and custom properties between Spira and Jira based on name matching. This feature can significantly reduce the manual configuration needed for property mapping.
How Auto-Mapping Works¶
- Name-Based Matching: The system looks for properties with identical or similar names in both systems and creates mappings automatically.
- Blank Mappings Only: Auto-mapping only applies to properties that haven't been manually mapped yet.
- Manual Mappings Still Available: You can still manually map properties and your previous manually mapped values are not overridden.
Benefits of Auto-Mapping¶
- Reduced Configuration Time: Minimizes the need to manually map each property
- Simplified Setup: Just provide the product's External Key and activate the sync
- Flexibility: You can still manually map properties to override any auto-mapping if needed
Best Practices for Auto-Mapping
For optimal results with auto-mapping:
- try to use consistent naming conventions between your Spira and Jira environments. Properties with identical or very similar names will be automatically matched, saving significant configuration time;
- after the first sync run, review the auto-created mappings to ensure they meet your needs. The dataSync will add a warning in the Event Log to indicate the properties that could not be automatically mapped;
- remember to check your custom list values as well;
Rules for name matching
The system ignores special characters, capitalization, spaces, and leading numbers when comparing names for auto-mapping. For example, "1-Medium-Priority", "Medium Priority", and "mediumPriority" would all be considered similar enough to match.
Even with auto-mapping enabled, you may still need to manually map some properties, especially if they have different names in the two systems or if you need specific mapping configurations.
What Fields Does Auto-Mapping Cover?
Auto-mapping works for the following field types:
Standard Fields (for Incidents, Requirements, and Tasks):
- Type
- Status
- Priority (Incidents and Tasks) / Importance (Requirements)
- Component
Custom Properties:
- All custom property types including Text, Integer, Decimal, Boolean, Date, User, Release, List, and Multi-List
- Both scalar properties (simple values) and list properties (with their values)
What Auto-Mapping Does NOT Cover:
- Release mappings (must be configured manually or created automatically during sync)
- Special fields like Issue Key, and Time Tracking (must be configured manually)
- User mappings (handled separately through user mapping configuration)
- The External Key for product activation (must be entered manually)
Auto-mapping saves significant time on standard field and custom property configuration, but you'll still need to manually configure special fields and activate the product with an External Key.
Using Spira with Jira¶
Now that all the mappings are done, you are now ready to use the integration.
Once the data sync service starts, at first any artifacts created in Spira for the specified products will be imported into Jira and any existing issues in Jira get loaded into Spira. Links between Jira issues will be imported as Requirements associations.
Checking the logs
At this point we recommend checking the event log for any errors or useful messages.
- Cloud or on premise: open the Event Log from Spira's System Administration menu
- On premise: you may see additional information on the web server. Open the Windows Event Viewer and choosing the Application Log. In this log any error messages raised by the Spira Data Sync Service will be displayed.
If you see any error messages, we recommend immediately stopping data-sync and checking the various mapping entries. If you cannot see any issues with the mapping information, we recommend sending a full copy of the event log message(s) to Inflectra customer services who will help you troubleshoot the problem.
To use Spira with Jira on an ongoing basis, we recommend:
- When running tests in Spira, defects found should be logged through the Test Execution Wizard as normal.
- Developers can log new defects into either Spira or Jira. In either case they will get loaded into the other system.
- Once created in one of the systems and successfully replicated to the other system, the incident should not be modified again inside Spira
- At this point, the incident should not be acted upon inside Spira and all data changes to the issue should be made inside Jira. To enforce this, you should modify the workflows set up in Spira so that the various fields are marked as inactive for all the incident statuses other than the "New" status. This will allow someone to submit an incident in Spira, but will prevent them making changes in conflict with Jira after that point.
- As the issue progresses through the customized Jira workflow, changes to the type of issue, changes to its status, priority, description and resolution will be updated automatically in Spira. In essence, Spira acts as a read-only viewer of these incidents.
You are now able to perform test coverage and incident reporting inside Spira using the test cases managed by Spira and the incidents managed on behalf of Spira inside Jira.
Using the Jira Cloud Connector¶
The Jira Cloud Connector is now "Spira QA Coverage".
This app is available for Jira Cloud on the Jira Marketplace
Troubleshooting¶
Data Synchronization Problems¶
Status synchronization issues
Symptoms: Status changes don't sync or cause errors
Solutions:
- Verify status mappings between Spira and Jira. If using Auto-Map, make sure the status names match
- Ensure Jira workflow allows the status transitions being attempted
- Try disabling the product template 'Status Bulk Edit' as explained here
- Review field requirements for each status in both systems
- Consider simplifying workflows during initial testing
Troubleshooting Best Practices¶
General Troubleshooting Steps
- Check Spira's Event Log first - Most issues are logged with detailed error messages
- Test with minimal configuration - Start with basic field mappings and add complexity gradually
- Verify permissions - Ensure users have appropriate access in both systems
- Use test data - Create test incidents/issues to verify sync behavior
When to Contact Support
Contact Inflectra Support if you encounter:
- Persistent authentication errors after verifying credentials
- Data corruption or loss during synchronization
- Performance issues that don't improve with configuration changes
- Error messages that aren't covered in this troubleshooting guide
Please include in your support request:
- Full error messages from the Event Log
- Your sync service details: cloud-hosted or on-premise (Windows service or desktop app)
- Your Spira environment: instance URL, hosting type (cloud or on-premise), and version number
- Screenshots of your configuration settings
- Description of what you were trying to accomplish
- Steps to reproduce the issue
-
Spira treats Releases as primary, independent artifacts with their own workflows, deep hierarchies, and testing relationships. ↩